一、介绍
ELK包括Elasticsearch(搜索分析)、Logstash(数据抽取)、Kibana(数据展现)三个开源软件的组成的一个整体。也称为ELK stack。
1.1 Elastic Stack简介
- Elasticsearch是一个基于Lucene的搜索服务器
- 提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
- 根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene
1.2 es特点
1.2.1 海量数据处理
1.2.2 开箱即用
1.2.3 作为传统数据库的补充
- 传统关系型数据库不擅长全文检索(MySQL自带的全文索引,与ES性能差距非常大)
- 传统关系型数据库无法支持搜索排名、海量数据存储、分析等功能
- Elasticsearch可以作为传统关系数据库的补充,提供RDBM无法提供的功能
1.2.4 ElasticSearch对比Solr
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
1.3 Lucene全文搜索库
1.3.1 全文检索
1.结构化数据与非结构化数据
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
2.搜索结构化数据和非结构化数据
- 使用SQL语言专门搜索结构化的数据
- 使用ES/Lucene/Solor建立倒排索引,根据关键字就可以搜索一些非结构化的数据
3.全文检索
- 通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
- 用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
- 类似于通过字典中的检索字表查字的过程
1.3.2 分词器与中文分词器
分词器是指将一段文本,分割成为一个个的词语的动作。例如:按照停用词进行分隔(的、地、啊、吧、标点符号等)。我们之前在代码中使用的分词器是Lucene中自带的分词器。这个分词器对中文很不友好,只是将一个一个字分出来,所以,就会从后出现上面的问题——无法搜索词语。
1.3.3 倒排索引结构
倒排索引是一种建立索引的方法。是全文检索系统中常用的数据结构。通过倒排索引,就是根据单词快速获取包含这个单词的文档列表。倒排索引通常由两个部分组成:单词词典、文档。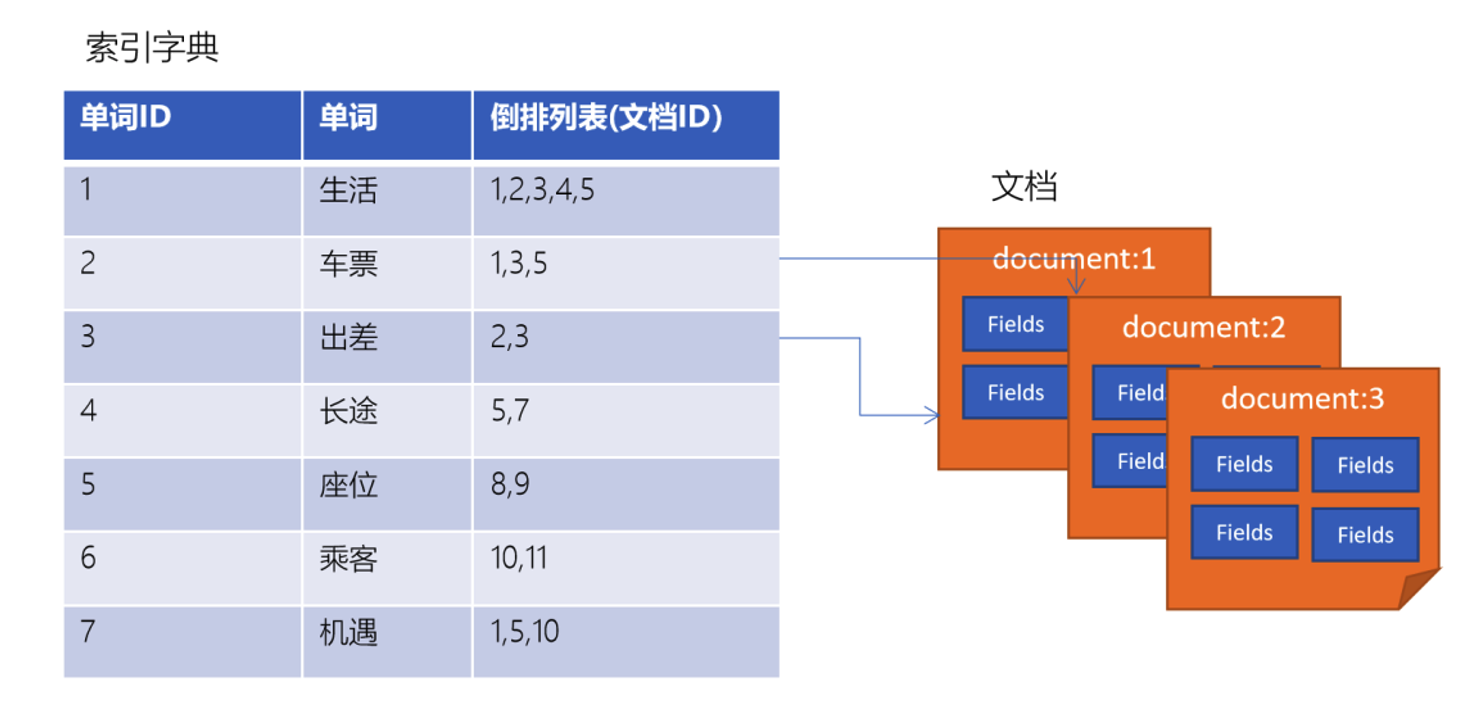
1.3.4 企业中为什么不直接使用Lucene
- Lucene的内建不支持分布式
- Lucene是作为嵌入的类库形式使用的,本身是没有对分布式支持。
- 区间范围搜索速度非常缓慢
- Lucene的区间范围搜索API是扩展补充的,对于在单个文档中term出现比较多的情况,搜索速度会变得很慢
- Lucene只有在数据生成索引文件之后(Segment),才能被查询到,做不到实时
- 可靠性无法保障
- 无法保障Segment索引段的可靠性
1.4 Elasticsearch中的核心概念
1.4.1 索引 index
- 一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
- 一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
- 在一个集群中,可以定义任意多的索引。
1.4.2 映射 mapping
- ElasticSearch中的映射(Mapping)用来定义一个文档
- mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的
1.4.3 字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
1.4.4 类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
1.4.5 文档 document
- 一个文档是一个可被索引的基础信息单元。比如,可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式
1.4.6 集群 cluster
- 一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
- 一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”
- 这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
1.4.7 节点 node
- 一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
- 一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中
- 这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中
- 在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
1.4.8 分片和副本 shards&replicas
1.分片
- 一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢
- 为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片
- 当创建一个索引的时候,可以指定你想要的分片的数量
- 每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
- 分片很重要,主要有两方面的原因
- 允许水平分割/扩展你的内容容量
- 允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的
2.副本
- 在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
- 副本之所以重要,有两个主要原因
- 在分片/节点失败的情况下,提供了高可用性。注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
- 每个索引可以被分成多个分片。一个索引有0个或者多个副本
- 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定
- 在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
二、restful
2.1 创建索引
2.1.1 创建带有映射的索引
Elasticsearch中,我们可以使用RESTful API(http请求)来进行索引的各种操作。创建MySQL表的时候,我们使用DDL来描述表结构、字段、字段类型、约束等。在Elasticsearch中,我们使用Elasticsearch的DSL来定义——使用JSON来描述。例如:PUT /my-index
{
"mapping": {
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
}
2.1.2 字段的类型
在Elasticsearch中,每一个字段都有一个类型(type)。以下为Elasticsearch中可以使用的类型:
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 简单类型 | text | 需要进行全文检索的字段,通常使用text类型来对应邮件的正文、产品描述或者短文等非结构化文本数据。分词器先会将文本进行分词转换为词条列表。将来就可以基于词条来进行检索了。文本字段不能用户排序、也很少用户聚合计算。 |
| 简单类型 | keyword | 使用keyword来对应结构化的数据,如ID、电子邮件地址、主机名、状态代码、邮政编码或标签。可以使用keyword来进行排序或聚合计算。注意:keyword是不能进行分词的。 |
| 简单类型 | date | 保存格式化的日期数据,例如:2015-01-01或者2015/01/01 12:10:30。在Elasticsearch中,日期都将以字符串方式展示。可以给date指定格式:”format”: “yyyy-MM-dd HH:mm:ss” |
| 简单类型 | long/integer/short/byte | 64位整数/32位整数/16位整数/8位整数 |
| 简单类型 | double/float/half_float | 64位双精度浮点/32位单精度浮点/16位半进度浮点 |
| 简单类型 | boolean | “true”/”false” |
| 简单类型 | ip | IPV4(192.168.1.110)/IPV6(192.168.0.0/16) |
| JSON分层嵌套类型 | object | 用于保存JSON对象 |
| JSON分层嵌套类型 | nested | 用于保存JSON数组 |
| 特殊类型 | geo_point | 用于保存经纬度坐标 |
| 特殊类型 | geo_shape | 用于保存地图上的多边形坐标 |
2.1.3 创建保存职位信息的索引
- 使用PUT发送PUT请求
- 索引名为 /job_idx
- 判断是使用text、还是keyword,主要就看是否需要分词
| 字段 | 类型 |
|---|---|
| area | text |
| exp | text |
| edu | keyword |
| salary | keyword |
| job_type | keyword |
| cmp | text |
| pv | keyword |
| title | text |
| jd | text |
创建索引:PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true},
"exp": { "type": "text", "store": true},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true},
"jd": { "type": "text", "store": true}
}
}
}
2.1.4 查看索引映射
使用GET请求查看索引映射// 查看索引映射
GET /job_idx/_mapping
使用head插件也可以查看到索引映射信息。
2.1.5 查看Elasticsearch中的所有索引
|
2.1.6 删除索引
|
2.1.7 指定使用IK分词器
因为存放在索引库中的数据,是以中文的形式存储的。所以,为了有更好地分词效果,我们需要使用IK分词器来进行分词。这样,将来搜索的时候才会更准确。PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"exp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"jd": { "type": "text", "store": true, "analyzer": "ik_max_word"}
}
}
}
2.2 PUT请求
前面我们已经创建了索引。接下来,我们就可以往索引库中添加一些文档了。可以通过PUT请求直接完成该操作。在Elasticsearch中,每一个文档都有唯一的ID。也是使用JSON格式来描述数据。例如:PUT /customer/_doc/1
{
"name": "John Doe"
}
- 如果在customer中,不存在ID为1的文档,Elasticsearch会自动创建
2.2.1 添加职位信息请求
|
Elasticsearch响应结果:{
"_index": "job_idx",
"_type": "_doc",
"_id": "29097",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
2.3 修改职位薪资
2.3.1 执行update操作
|
2.3.2 删除一个职位数据
|
2.4 批量导入JSON数据
2.4.1 bulk导入
为了方便后面的测试,我们需要先提前导入一些测试数据到ES中。在资料文件夹中有一个job_info.json数据文件。我们可以使用Elasticsearch中自带的bulk接口来进行数据导入。
- 上传JSON数据文件到Linux
- 执行导入命令
curl -H "Content-Type: application/json" -XPOST "node1.itcast.cn:9200/job_idx/_bulk?pretty&refresh" --data-binary "@job_info.json"
2.4.2 查看索引状态
|
通过执行以上请求,Elasticsearch返回数据如下:[
{
"health": "green",
"status": "open",
"index": "job_idx",
"uuid": "Yucc7A-TRPqnrnBg5SCfXw",
"pri": "1",
"rep": "1",
"docs.count": "6765",
"docs.deleted": "0",
"store.size": "23.1mb",
"pri.store.size": "11.5mb"
}
]
2.5 5.7 根据ID检索指定职位数据
在Elasticsearch中,可以通过发送GET请求来实现文档的查询。GET /job_idx/_search
{
"query": {
"ids": {
"values": ["46313"]
}
}
}
2.6 根据关键字搜索数据
检索jd中销售相关的岗位GET /job_idx/_search
{
"query": {
"match": {
"jd": "销售"
}
}
}
除了检索职位描述字段以外,我们还需要检索title中包含销售相关的职位,所以,我们需要进行多字段的组合查询。GET /job_idx/_search
{
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
}
}
2.7 根据关键字分页搜索
在存在大量数据时,一般我们进行查询都需要进行分页查询。例如:我们指定页码、并指定每页显示多少条数据,然后Elasticsearch返回对应页码的数据。
2.7.1 使用from和size来进行分页
在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页。
from = (page – 1) * sizeGET /job_idx/_search
{
"from": 0,
"size": 5,
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
}
}
2.7.2 使用scroll方式进行分页
前面使用from和size方式,查询在1W-5W条数据以内都是OK的,但如果数据比较多的时候,会出现性能问题。Elasticsearch做了一个限制,不允许查询的是10000条以后的数据。如果要查询1W条以后的数据,需要使用Elasticsearch中提供的scroll游标来查询。
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。使用scroll查询后,排序后的数据会保持一定的时间,后续的分页查询都从该快照取数据即可。
1.第一次使用scroll分页查询
此处,我们让排序的数据保持1分钟,所以设置scroll为1mGET /job_idx/_search?scroll=1m
{
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
},
"size": 100
}
执行后,我们注意到,在响应结果中有一项:_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAGgWT3NxUFZ2OXVRVjZ0bEIxZ0RGUjMtdw==
后续,我们需要根据这个_scroll_id来进行查询
2.第二次直接使用scroll id进行查询
|
2.8 统计分析案例
2.8 1 案例介绍
有以下数据集:
| 订单ID | 订单状态 | 支付金额 | 支付方式ID | 用户ID | 操作时间 | 商品分类 |
|---|---|---|---|---|---|---|
| id | status | pay_money | payway | userid | operation_date | category |
| 1 | 已提交 | 4070 | 1 | 4944191 | 2020-04-25 12:09:16 | 手机 |
| 2 | 已完成 | 4350 | 1 | 1625615 | 2020-04-25 12:09:37 | 家用电器,电脑 |
| 3 | 已提交 | 6370 | 3 | 3919700 | 2020-04-25 12:09:39 | 男装,男鞋 |
| 4 | 已付款 | 6370 | 3 | 3919700 | 2020-04-25 12:09:44 | 男装,男鞋 |
我们需要基于按数据,使用Elasticsearch中的聚合统计功能,实现一些指标统计。
2.8.2 创建索引
|
2.8.3 导入测试数据
- 上传资料中的order_data.json数据文件到Linux
- 使用bulk进行批量导入命令
|
2.8.4 统计不同支付方式的的订单数量
1.使用JSON DSL的方式来实现
这种方式就是用Elasticsearch原生支持的基于JSON的DSL方式来实现聚合统计。GET /order_idx/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "payway"
}
}
}
}
统计结果:"aggregations": {
"group_by_state": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 2,
"doc_count": 1496
},
{
"key": 1,
"doc_count": 1438
},
{
"key": 3,
"doc_count": 1183
},
{
"key": 0,
"doc_count": 883
}
]
}
}
这种方式分析起来比较麻烦,如果将来我们都是写这种方式来分析数据,简直是无法忍受。所以,Elasticsearch想要进军实时OLAP领域,是一定要支持SQL,能够使用SQL方式来进行统计和分析的。
2.基于Elasticsearch SQL方式实现
|
这种方式要更加直观、简洁。
2.8 批量操作
2.8.1 bulk导入
为了方便后面的测试,我们需要先提前导入一些测试数据到ES中。在资料文件夹中有一个job_info.json数据文件。我们可以使用Elasticsearch中自带的bulk接口来进行数据导入。
语法POST /_bulk
{ "action": { "metadate" } }
{ "data" }
如{ "create": { "_index": "text_index", "_id": "8" } }
{ "test_field": "test9" }
总结
- 功能
- delete: 删除一个文档,只要1个json串就可以
- create: 相当于强制创建,PUT /index/type/id/_create
- index: 普通的put操作,可以是创建文档,也可以是全量替换文件
- update: 执行的是局部更新partial update操作
- 格式: 每个json不能换行。相邻json必须换行。
- 隔离: 每个操作互不影响。操作失败的行会返回其失败信息。
- 实际用法: bulk请求一次不要太大,否则一下积压到内存中,性能会下降。所以,一次请求几千个操作、大小在几m正好。
三、分布式
3.1 分布式基础
3.1.1 es对复杂分布式机制的透明隐藏特性
- 分布式机制:分布式数据存储及共享
- 分片机制:数据存储到哪个分片,副本数据写入。
- 集群发现机制:cluster discovery。新启动es实例,自动加入集群。
- shard负载均衡:大量数据写入及查询,es会将数据平均分配。
- shard副本:新增副本数,分片重分配。
3.1.2 es的垂直扩容与水平扩容
- 垂直扩容:使用更加强大的服务器代替老服务器,但单机存储及运算能力有上线,且成本直线上升。
- 水平扩容:采购更多服务器,加入集群,大数据。
3.1.3 增减或减少节点时的数据rebalance
新增或减少es实例时,es集群会将数据重新分配。
3.1.4 master节点
功能:
- 创建删除节点
- 创建删除索引
3.1.5 节点对等的分布式架构
- 节点对等,每个节点都能接收所有的请求
- 自动请求路由
- 响应收集
3.2 分片shard、副本replica机制
- 每个index包含一个或多个shard
- 每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
- 增减节点时,shard会自动在nodes中负载均衡
- primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
- replica shard是primary shard的副本,负责容错,以及承担读请求负载
- primary shard的数量在创建索引的时候就固定了,replica shard 的数量可以随时修改
- primary shard 的默认数量是1,replica默认是1,默认共有两个shard,1个primary shard,1个replica shard(注意:es7以前primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard)
- primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
3.2.1 实例1
- 单个node环境中,创建一个index,有3个primary,3个replica
- 集群status是yellow
- 这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
- 集群是可以工作的,但是一旦出现节点宕机,数据全部丢失,且集群不可用,无法承接任何请求
3.2.2 实例2
- replica shard 分配;3个primary shard,1个replica shard,2个node
- 同步:primary
-->replica - 读请求:primary/replica
3.3 横向扩容
- 分片自动负载均衡,分配向空闲机器转移
- 每个节点存储更少分配,系统资源给予每个分片的资源更多,整体集群性能提高
- 扩容极限:节点数大于整体分片数,则必有空闲机器
- 超出扩容极限时,可以增加副本数为2,总共3x3=9个分片。9台机器同时运行,存储和搜索性能更强,容错性更好
- 容错性:只要一个索引的所有主分片在,集群就可以运行
3.4 es容错机制master选举,replica容错,数据恢复
以3分配,2副本数,3节点为例介绍
- master node宕机,自动master选举,集群为red
- replica容错:新master将replica提升为primary shard,yellow
- 重启宕机node,master copy replica到该node,使用原有的 shard并同步宕机后的修改,green
四、文档存储机制
4.1 数据路由
4.1.1 文档存储如何路由到相应分片
一个文档,最终会落在主分片的一个分片上,到底应该在哪个分片,这就是数据路由。
4.1.2 路由算法
|
哈希值对主分片数去模
举例:
对一个文档进行crud时,都会带有一个路由值 routing number。默认文档_id(可能是手动指定,可能是自动生成)。
存储1号文档,经过哈希计算,哈希值为2,此索引有3个主分片,那么计算2%3=2,就算出此文档在P2分片上。
决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的。
无论hash值是多少,对number_of_premary_shards求余数,结果一定是0-number_of_primary_shards-1之间这个范围内的。
4.1.3 手动指定 routing key
|
场景:在程序中,架构师可以手动指定已有数据的一个属性为路由值,好处是可以定制一类文档数据存储到一个分片中,缺点是设计不好,会造成数据倾斜。
所以,不同文档尽量放到不同的索引中,剩下的交给es集群。
4.1.4 主分片数量不可变
涉及到以往数据的查询搜索,所以一旦建立索引,主分片数不可变。
4.2 文档的增删改查内部机制
增删改可以看作是update,都是对数据的改动。一个改动请求发送到es集群,经历一下四个步骤:
- 客户端选择一个node发送请求过去,这个node就是coordination node(协调节点)
- coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
- 实际的node上的primary shard处理请求,然后将数据同步到replica node
- coordinating node,如果发现primary node和所有replica node都搞定之后,就返回相应结果给客户端。
4.3 文档的查询内部机制
- 客户端发送请求到任意一个node,成为coordinating node
- coordinating node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
- 接收请求的node返回document给coordinating node
- coordinating node 返回document给客户端
- 特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了
4.4 bulk api奇特的json格式
|
- bulk中的每个操作都可能要转发到不同的node的shard去执行
- 如果采用比较良好的json数组格式
允许任意的换行,整个可读性非常棒,读起来很爽,es拿到那种标准格式的json串以后,要按照下述流程去进行处理:- 将json数组解析为jsonarray对象,这个时候整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是jsonarray对象
- 解析json数组中的每个json,对每个请求中的document进行路由
- 为路由到同一个shard上的多个请求,创建一个请求数组。100请求中有10个是到P1
- 将这个请求数组序列化
- 将序列化后的请求数组发送到对应节点上去
消耗更多内存,更多的jvm gc开销
bulk size 最佳大小的问题,一般来说在几千条,然后大小在10MB左右,但是可怕的来了,假如现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB=1GB,然后每个请求的json都copy一份jsonarray对象,此时内存中的占用就会翻倍,2GB内存,甚至不止。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能极速下降。
另外,占用内存越多,就会导致java虚拟机的垃圾回收次数越多,更频繁,回收越多,消耗的时间越多,导致es的java虚拟机停止工作线程的时间更多。现在的奇特格式
POST /_bulk
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n- 不用将其转换为json对象,不会出现内存中的相同数据的拷贝,而是直接切割json
- 对每两个一组的json,读取meta,进行document路由
- 直接将对应的json发送到node上去
最大的优势在于,不需要将json数组解析为一个jsonarray对象,形成一份大数据拷贝,浪费内存空间,尽可能的保证性能。
五、Mapping映射入门
5.1 什么是mapping映射
概念:自动或手动为index中的_doc建立的一种数据结构和相关配置,简称为mapping映射。
插入下面几条数据,让es自动为我们建立索引PUT /website/_doc/1
{
"post_data": "2019-01-01",
"title": "my first article",
"content": "this is xxxxx",
"author_id": 114400
}
PUT /website/_doc/2
{
"post_data": "2019-01-02",
"title": "my second article",
"content": "this is xxxxx",
"author_id": 114400
}
PUT /website/_doc/3
{
"post_data": "2019-01-03",
"title": "my third article",
"content": "this is xxxxx",
"author_id": 114400
}
对比数据库建表:create table websit (
post_data date,
title varchar(50),
content varchar(50),
author_id int(11)
);
动态映射:dynamic mapping,自动为我们建立index,以及对应的mapping,mapping中包含了每个field对应的数据类型,以及如何分词等设置。
重点:当然也可以手动在创建数据之前,先创建index,以及对应的mapping。GET /website/_mapping/
{
"website": {
"mappings": {
"properties": {
"author_id": {
"type": "long"
},
"content": {
"type": "text",
"fields": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_data": {
"type": "date"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
尝试各种搜索GET /website/_search?q=2019 1结果
GET /website/_search?q=2019-01-01 1结果
GET /website/_search?q=post_data:2019-01-01 1结果
GET /website/_search?q=post_data:2019 1结果
GET /website/_search?q=xxxxx 0结果
GET /website/_search?q=third 0结果
搜索结果为什么不一致,因为es自动建立mapping的时候,设置了不同的field不同的data type。不同的data type的分词、搜索等行为是不一样的。所以出现了_all field和post_data field的搜索表现完全不一样。
5.2 精确匹配与全文搜索的对比分析
5.2.1 exact value 精确匹配
2019-01-01,exact value,搜索的时候,必须输入2019-01-01,才能搜索出来
如果输入一个01,是搜索不出来的,type=date是,是精确匹配select * from book where post_date='2019-01-01'
5.2.2 full text 全文检索
搜“笔记电脑”,笔记本电脑词条不会出现。select * from book where name like '%笔记电脑%'
- 缩写
vs.全称:cnvschina - 格式转化:like liked likes
- 大小写:Tom vs tom
- 同义词:like vs love
就不是说单纯的只是匹配完整的一个值,而是可以对值进行拆分词语后(分词)进行匹配,也可以通过缩写、时态、大小写、同义词等进行匹配。深入NLP,自然语义处理。
5.3 全文检索下倒排索引核心原理快速揭秘
分词,初步的倒排索引的建立doc1: i really liked my small dogs, and i think my mom also liked them.
doc2: he never liked and dogs, so i hope that my mom will not expect me to liked him.
搜索mother like little dog,在搜索前先分词,然后逐一与doc中的分词进行对比,但是目前不可能有结果。
重建倒排索引
normalization正规化,建立倒排索引的时候,会执行一个操作,也就是说对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率。
时态的转换,单复数的转换,同义词的转换,大小写的转换mom -> mother
liked -> like
small -> little
dogs -> dog
重新建立倒排索引,加入normalization,再次用mother liked little dog搜索,就可以搜索到了。
5.4 分词器analyzer
5.4.1 什么是分词器analyzer
作用:切分词语,normalization(提升recall召回率)
给es一段句子,然后将这段句子拆分成一个个单个的单词,同时对每个单词进行normalication(时态转换,单复数转换)。
recall:召回率,搜索的时候,增加能够搜索到的结果的数量。
analyzer由三个部分组成:
- character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的,过滤html标签,
& -> and - tokenizer:分词,
hello you and me -> hello,you,and,me - token filter:lowercase,stop word,synonymom,
dogs -> dog,liked -> like,Tom -> tom,a/the/an -> 去除,mother -> mom,small -> little(stop word停词器:了的呢)
一个分词器很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引。
5.4.2 内置分词器的介绍
例句:Set the shape to semi-transparent by calling set_trans(5)
- standard analyzer标准分词:set,the,shape,to,semi,transparent,by,calling,set_trans,5(默认的是Standard)
- simple analyzer简单分词器:set,the,shape,to,semi,transparent,by,calling,set_trans
- whitespace analyzer:Set,the,shape,to,semi-transparent,by,calling,set_trans(5)
- language analyzer(特定的语言的分词器,比如english):set,shape,semi,transparent,call,set_trans,5
5.5 query string 根据字段分词策略
5.5.1 query string 分词
query string 必须以和index建立时相同的analyzer进行分词
query string 对exact value和fulltext的区别对待
如date: exact value精确匹配
text: full text全文检索
5.5.2 测试分词器
|
结果如下{
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
}
}
- token实际存储的term关键字
- position在此词条在原文中的位置
- start_offset/end_offset字符在原始字符串中的位置
5.6 mapping回顾
- 往es里面直接插入数据,es会自动建立索引,同时建立对应的mapping
- mapping中就自动定了每个field的数据类型
- 不同的数据类型,可能有的是exact value,有的是full text
- exact value,在建立倒排索引的时候,分词的时候,是将整个值要一起作为一个关键词建立倒排索引中的;full text,会经历各种各样的处理,分词,normalization(时态转换,同义词转换,大小写转换),才会建立到倒排索引中。
- 同时,exact value和full text 类型的field就决定了,在一个搜索过来的时候,对exact value field或者是full text field进行搜索的行为也是不一样的,会跟建立倒排索引的行为保持一致;比如说exact value搜索的时候,就是直接按照整个值进行匹配,full text query string,也会进行分词和normalization再去倒排索引中去搜索。
- 可以用es的dynamic mapping,让其自动建立mapping,包括自动设置数据类型;也可以提前手动创建index和tmapping,自己对各个field进行设置,包括数据类型,索引行为,分词器等。
5.7 mapping的核心数据类型以及dynamic mapping
5.7.1 核心的数据类型
下面展示部分类型:
string: text and keyword
byte、short、integer、long、float、double
boolean
date
5.7.2 dynamic mapping 推测规则
true or false -> boolean123 -> long123.45 -> double2019-01-01 -> date"hello world -> text/keyword"
5.7.3 查看mapping
|
5.8 手动管理mapping
5.8.1 查询所有索引的映射
GET /_mapping
5.8.2 创建映射!!
创建索引后,应该立即手动创建映射PUT book/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
},
"pic": {
"type": "text",
"index": false
},
"studymodel": {
"type": "text"
}
}
}
Text文本类型
analyzer
通过analyzer属性指定分词器。
上边指定了analyzer是指在索引和搜索都是用english,如果单独想定义搜索时使用的分词器则可以通过saerch_analyzer属性。index
index属性指定是否索引。
默认index=true,即要进行索引,只能进行索引才可以从索引库搜索到。
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置为false。
删除索引,重新创建映射,将pic的index设置为false,尝试根据pic去搜索,结果搜索不到数据。store
是否在source之外存储,每个文档索引后会在ES中保存一份原始文档,存放在source中,一般情况下不需要设置store为true,因为在source中已经有一份原始文档了。
测试PUT /index_name/_doc/1
{
...
}
keyword关键字字段
目前已经取代了index:false。之前介绍的text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,索引创建keyword字段的索引时是不进行分词的。keyword字段通常用于过滤、排序、聚合等。
date日期类型
日期类型不用设置分词器。通常日期类型的字段用于排序。
format,通过format设置日期格式。
例子:
下边的设置允许date字段存储年月日时分秒、年月日及毫秒三种格式。{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
}
}
}
数值类型
下面是es支持的数值类型
| 类型名称 |
|---|
| long |
| integer |
| short |
| byte |
| double |
| float |
| half_float |
| scaled_float |
- 尽量选择范围小的类型,提高搜索效率
- 对于浮点数尽量用比例因子, 比如一个价格字段,单位为元,将比例因子设置为100,这在es中会按分存储。
"price": {
"type": "scaled_float",
"scaling_factor": 100
},
5.8.3 修改映射
只能创建index时,手动建立mapping,或者新增field mapping,但是不能修改field mapping。
因为已有数据按照映射早已分词存储好。如果修改,那这些存储的数据怎么办。
新增一个字段mappingPUT /book/_mapping
{
"properties": {
"new_field_name": {
"type": "text",
"index": "false"
}
}
}
5.8.4 删除映射
通过删除索引来删除映射。
5.9 复杂数据类型
5.9.1 multivalue field
{“tags”: [“tag1”, “tag2”]}
建立索引时与string时语言的,数据类型不能混。
5.9.2 empty field
null、[]、[null]
5.9.3 object field
|
address: object 类型
查询映射:GET /company/_mapping
object数据:{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2019-01-01"
}
底层存储格式{
"address.country": [china],
"address.province": [guangdong],
"address.city": [guangzhou],
"name": [jack],
"age": [27],
"join_date": [2019-01-01]
}
对象数组:{
"author": [
{ "age": 26, "name": "Jack White" },
{ "age": 55, "name": "Tom Jones" },
{ "age": 39, "name": "Kiity Smith" },
]
}
底层存储格式:{
"author.age": [26, 55, 39],
"author.name": ["Jack White", "Tom Jones", "Kiity Smith"]
}
六、索引 Index 入门
6.1 索引管理
6.1.1 为什么需要手动创建索引
直接PUT数据,es会自动生成索引,并建立动态映射dynamic mapping。
在生产上,我们需要自己手动建立索引和映射,为了更好的管理索引。就像数据库的建表语句一样。
6.1.2 索引管理
1 创建索引
创建索引语法PUT /index
{
"settings": {},
"mappings": {
"properties": {
}
},
"aliases": {
"default_index": {}
}
}
例如PUT my_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"field1": {
"type": "text"
},
"field2": {
"type": "text"
}
}
},
"aliases": {
"default_index": {}
}
}
2 查询索引
|
3 修改索引
修改副本数PUT my_index/_settings
{
"number_of_replicas": 2
}
4 删除索引
|
为了安全起见,防止恶意删除索引,删除时必须指定索引名的配置:elasticsearch.yml
action.destructive_requires_name: true
6.2 定制分词器
6.2.1 默认的分词器
standard
分词三个组件:character filter, tokenizer, token filter。
- standard tokenizer:以单词边界进行切分
- standard token filter:什么都不做
- lowercase token filter:将所有字母转换为小写
- stop token filer(默认被禁用):移除停用词,比如a、the、it等
6.2.2 修改分词器的设置
启用english停用词token filterPUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopword": "_english_"
}
}
}
}
}
6.2.3 定制化自己的分词器
|
测试GET my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "tom&jerry are a friend in the house,<a>"
}
6.3 type 底层结构及弃用原因
6.3.1 type 是什么
type,是一个index中用来区分类似的数据的,类似的数据,但是可能有不同的fields,而且有不同的属性来控制索引建立,分词器。
field的value,在底层的lucene中建立索引的时候,全部都是opaque bype类型,不区分类型的。
lucene是没有type的概念,在document中,实际上将type作为一个document的field来存储,即type,es通过type来进行type的过滤和筛选。
6.3.2 es 中不同 type 存储机制
一个index中的多个type,实际上是放在一起存储的,因此一个index下,不能有多个type重名,二类型或者其他设置不同的,因为那样是无法处理的。{
"goods": {
"mappings": {
"electronic_goods": {
"properties": {
"name": {
"type": "string"
},
"price": {
"type": "double"
},
"service_period": {
"type": "string"
}
}
},
"fresh_goods": {
"properties": {
"name": {
"type": "string"
},
"price": {
"type": "double"
},
"eat_period": {
"type": "string"
}
}
}
}
}
}
测试PUT /goods/electronic_goods/1
{
"name": "A",
"price": 11.1,
"service_period": "one"
}
PUT /goods/fresh_goods/1
{
"name": "B",
"price": 21.1,
"eat_period": "two"
}
es文档在底层的存储是这样的:{
"goods": {
"mappings": {
"_type": {
"type": "string",
"index": false
},
"name": {
"type": "string"
},
"price": {
"type": "double"
},
"service_period": {
"type": "string"
}
"eat_period": {
"type": "string"
}
}
}
}
底层数据存储格式{
"_type": "electronic_goods",
"name": "A",
"price": 11.1,
"service_period": "one",
"eat_period": ""
}
{
"_type": "fresh_goods",
"name": "B",
"price": 21.1,
"service_period": "",
"eat_period": "two"
}
6.3.3 type 弃用
同一索引下,不同type的数据存储其他type的field大量空值,造成资源浪费。索引,不同数据类型,要放到不同的索引下。
es9中将会彻底删除type。
6.4 定制dynamic mapping
6.4.1 定制dynamic策略
- true:遇到陌生字段,就进行dynamic mapping
- false:新监测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但将出现在返回点击的源字段中。这些字段不会添加到映射中,必须显式添加新字段。
- strict:遇到陌生字段,就报错
创建mappingPUT /my_index1
{
"mappings": {
"dynamic": false,
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": true
}
}
}
}
插入数据PUT my_index1/_doc/1
{
"title": "my name",
"content": "hello",
"address": {
"province": "hangzhou",
"city": "hangzhou"
}
}
但是当我们指定搜索content中的内容是搜索不到的GET my_index1/_search?q=content:hello
因为我们在外层dynamic中设置了false,因此他虽然可以添加成功并且在无条件搜索时可以带出来,但是内容搜索是无法找到的。
6.4.2 自定义dynamic mapping策略
es会根据传入的值,推断类型。
1.date_detection 日期探测
默认会按照一定格式识别date,比如yyyy-MM-dd。但是如果某个field先过来一个2017-01-01的值,就会被自动dynamic mapping成date,后面如果再来一个"hello"之类的值,就会报错。可以手动关闭某个type的date_detection,如果有需要,自己手动指定某个field为date类型。PUT my_index
{
"mappings": {
"date_detection": true,
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": true
}
}
}
}
2.自定义日期格式
|
3.numeric_detection 数字探测
虽然json支持本机浮点和整数数据类型,但某些应用程序或语言有时可能将数字呈现为字符串。通常正确的解决方案是显式地映射这些字段,但是可以启用数字检测(默认下禁用)来自动完成这些操作。PUT my_index
{
"mappings": {
"numeric_detection": true
}
}
测试PUT my_index/_doc/1
{
"my_float": "1.0",
"my_integer": "1"
}
6.4.3 定制自己的dynamic mapping template
|
插入数据PUT my_index/_doc/1
{
"title": "this is my first article"
}
PUT my_index/_doc/2
{
"title_en": "this is my first article"
}
查询数据GET my_index/_search?q=is
模版参数"match": "long_*"
"unmatch": "long_*"
"match_mapping_type": "string""
"path_match": "long.*"
"path_unmatch": "long.*"
"match_pattern": "regex"
"match": "^profit_\d+$"
场景
结构化搜索
默认情况下,es将字符串字段映射为带有子关键字字段的文本字段。但是,如果只对结构化内容进行索引,而对全文搜索不感兴趣,则可与你将字段映射为关键字。请注意,这意味着为了搜索这些字段,必须搜索索引所使用的完全相同的值。{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}仅搜索
与前面的实例相反,如果您只关心字符串字段的全文搜索,并且不打算对字符串字段运行聚合、排序或精准搜索,可以告诉弹性搜索将其仅映射为文本字段。{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "text"
}
}
}norms 不关心评分
norms是指标时间的评分因此。如果不关心评分,例如,如果从不按评分对文档进行排序,则可以在搜索中禁用这些评分因子的存储并节省一些空间。{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
6.5 零停机重建索引
6.5.1 零停机重建索引
场景
一个field的设置是不能被修改的,如果要修改一个field,那么应该重新按照新的mapping,建立index,然后将数据批量查询出来,重新用bulk api写入index中。
批量查询的时候,建议采用scroll api,并且采用多线程兵法的方式reindex数据,每次scroll就查询指定日期的一段数据,交给一个线程即可。
- 一开始,依靠dynamic mapping,插入数据,但是不小心有些数据是2019-09-10这种日期格式的,所以title这种field被自动映射为date类型,实际上他应该是string类型的
PUT my_index/_doc/1
{
"title": "2019-01-01"
}
PUT my_index/_doc/2
{
"title": "2019-01-02"
} - 当后期想索引种加入string类型的title值的时候,就会报错
PUT my_index/_doc/3
{
"title": "hello"
} - 报错
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [title] of type [date] in document with id '3'. Preview of field's value: 'hello'"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [title] of type [date] in document with id '3'. Preview of field's value: 'hello'",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse date field [hello] with format [strict_date_optional_time||epoch_millis]",
"caused_by" : {
"type" : "date_time_parse_exception",
"reason" : "Failed to parse with all enclosed parsers"
}
}
},
"status" : 400
} - 此时,唯一的办法,就是进行reindex,也就是说,重新建立一个索引,将旧索引的数据查询出来,再导入新索引。
- 如果说旧索引的名字是old_index,新索引的名字是new_index,终端为java应用,已经在使用old_index在操作了,难道还要去停止java应用,修改使用的index为new_index,再重新启动java应用吗?这个过程种就会导致java应用停机,可用性降低。
- 所以说,给java应用一个别名,这个别名是指像旧索引的,java应用先用着,java应用先用prop_index alias来操作,此时实际只想的是旧的my_index。
PUT my_index/_alias/prop_index - 新建一个index,调整其title的类型为string
PUT my_index_new
{
"mappings": {
"properties": {
"title": {
"type": "text"
}
}
}
} - 使用scroll api将数据批量查询出来返回
GET my_index/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 1
}{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFFJvR3Q3SUlCZlJjeEhGdG5TNGh5AAAAAAAK618WT0FMLV9RRTFUMUd6TlA2RVdDNkpQQQ==",
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "2019-01-01"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "2019-01-02"
}
}
]
}
} - 使用bulk api将scroll查出来的一批数据,批量写入新索引
PUT _bulk
{"index": {"_index": "my_index_new", "_id" : "1"}}
{"title" : "2019-01-01"} - 反复循环8-9,查询一批数据,bulk导入
- 将prop_index alias切换到my_index_new上去,java应用就会直接通过index别名使用新的索引中的数据。
POST /_aliases
{
"actions": [
{
"remove": {
"index": "my_index",
"alias": "prop_index"
}
},
{
"add": {
"index": "my_index_new",
"alias": "prop_index"
}
}
]
} - 直接通过prod_inidex来查询
6.5.2 生产实战:基于alias对client透明切换index
对索引的增删使用index_name
对数据的处理使用index_aliase
当发生上面场景是,需要对数据切换至新的index中,并切换index_aliase至新的index中,这样就完成了无需服务停机的切换索引功能。
七、中文分词器 IK分词器
7.1 IK分词器安装使用
7.1.1 中文分词器
standard分词器仅适用于英文。GET /_analyze
{
"analyzer": "standard",
"text": "老杨来了"
}
IK分词器是目前最流行的es中文分词器。
7.1.2 安装
下载:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.9.3
配置到plugins中,并重启es。
7.1.3 ik分词器基础知识
- ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分成“中华人民共和国”、“中华人民”、“中华”、“华人”、“人民共和国”、“人民大会堂”,会穷尽各种可能的组合。
- ik_smart:会做最粗粒度的拆分,比如上面只会拆分为“中华人民共和国”、“人民大会堂”。
7.1.4 ik分词器的使用
存储时,使用ik_max_word,搜索时,使用ik_smartPUT test
{
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
搜索如下信息:GET /my_index/_search?q=会堂
7.2 IK配置文件
7.2.1 ik分词器配置文件
ik配置文件地址:es/plugins/ik/config目录
- IKAnalyzer.cfg.xml:用来配置自定义词库
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,就会被分在一起
- preposition.dic:介词
- quantifier.dic:放了一些单位相关的词,量词
- suffix.dic:放了一些后缀
- surname.dic:中国的姓氏
- stopword.dic:英文停用词
ik原生最重要的两个配置文件
- main.dic:包含了原生的中文词语,会按照这个里面的词法去分词
- stopword.dic:包含了英文的停用词
7.2.2 自定义词库
- 自己建立词库:每年会涌现一些特殊的流行词,网红、喊麦、鬼畜,一般不会在ik的原生词库
自己补充自己的最新词语,在ik的词库里面
IKAnalyzer.cfg.xml:ext_dict,创建mydic.dic补充自己的词语,然后需要重启es,才能生效 - 自己建立停用词库:比如了、的、啥、么,不需要去建立索引,让大家搜索
custom/ext_stopword.dic,以及有了常用的中文停用词
7.3 使用mysql热更新词库
7.3.1 热更新
每次都是在es的扩展词典中,手动添加新词语,很坑。
- 每次添加完,都需要重启es才生效
- es是分布式的,可能有多个节点,不能每次都一个个节点上去修改
es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载这些新词语
热更新方法:
- 基于ik分词器原生支持的热更新方法,部署一个web服务器,提供一个http接口,通过modified和tag两个http响应头,来提供词语的热更新
- 修改ik分词器源码,然后手动支持这些从mysql中每隔一定时间,自动加载的词库
第一种,ikgit社区官方都不建议采用,使用第二种方案
7.3.2 步骤
下载源码 https://github.com/medcl/elasticsearch-analysis-ik/releases
ik分词器,是个标准的java maven工程,直接导入eclipse就可以看到源码修改源代码
- org.wltea.analyzer.dic.Dictionary类,160行Dictionary单例类的初始化方法,在这里需要创建一个我们自定义的线程,并启动它
- org.wltea.analyzer.dic.HotDictReloadThread类:就是死循环,不断调用Dictionary.getSingleton().reLoadMainDict(),去重新加载词典
- Dictionary类:399行,this.loadMySQLExtDict();加载mysql字典
- Dictionary类:609行,this.loadMySQLStopwordDict();加载mysql停用词
- config下jdbc-reload.properties。mysql配置文件
mvn package打包
target\releases\elasticsearch-analysis-ik-7.3.0.zip解压缩ik压缩包
将mysql驱动jar,放入ik的目录下修改jdbc配置
重启es