[张汉东大佬github下的图]https://github.com/ZhangHanDong/inviting-rust
[转自]https://cloud.tencent.com/developer/article/1902537
[转自]https://cloud.tencent.com/developer/article/1792684
基于遍历的编译器架构
所谓 遍历(Pass) ,就是对 代码 / AST 扫描并进行处理。
编译分为前端和后端。前端负责生成 AST ,而后端用于生成机器码。
编译流程的每一步都被抽象为 Pass。
遍历分为两类
- 分析(analysis)遍历,负责收集信息供其他 Pass 使用,辅助调试或使程序可视化
- 变换 (transform)遍历,用于改变程序的数据流或控制流,比如优化等
编译器的两大阶段:分析阶段和综合阶段。编译器前端一般对应于 分析阶段,编译器后端对应于综合阶段。
- 前者从给定的源码文本创建出一个中间表示
- 后者从中间表示创建等效的目标程序。
编译器前端又包括以下几部分
- 词法分析器
- 语法分析器
- 语义分析器
- 中间代码生成器
- 代码优化器
目标代码生成则由后端完成。
在 词法分析、语法分析和语义分析阶段,编译器会创建和维护一个重要的数据结构,用于跟踪变量的语义,即它会存储有关的信息和名称的绑定信息等,叫做 符号表(Symbol Table)。在中间代码生成和目标代码生成过程中会使用它。
基于按需驱动的编译器架构(Rust编译器)
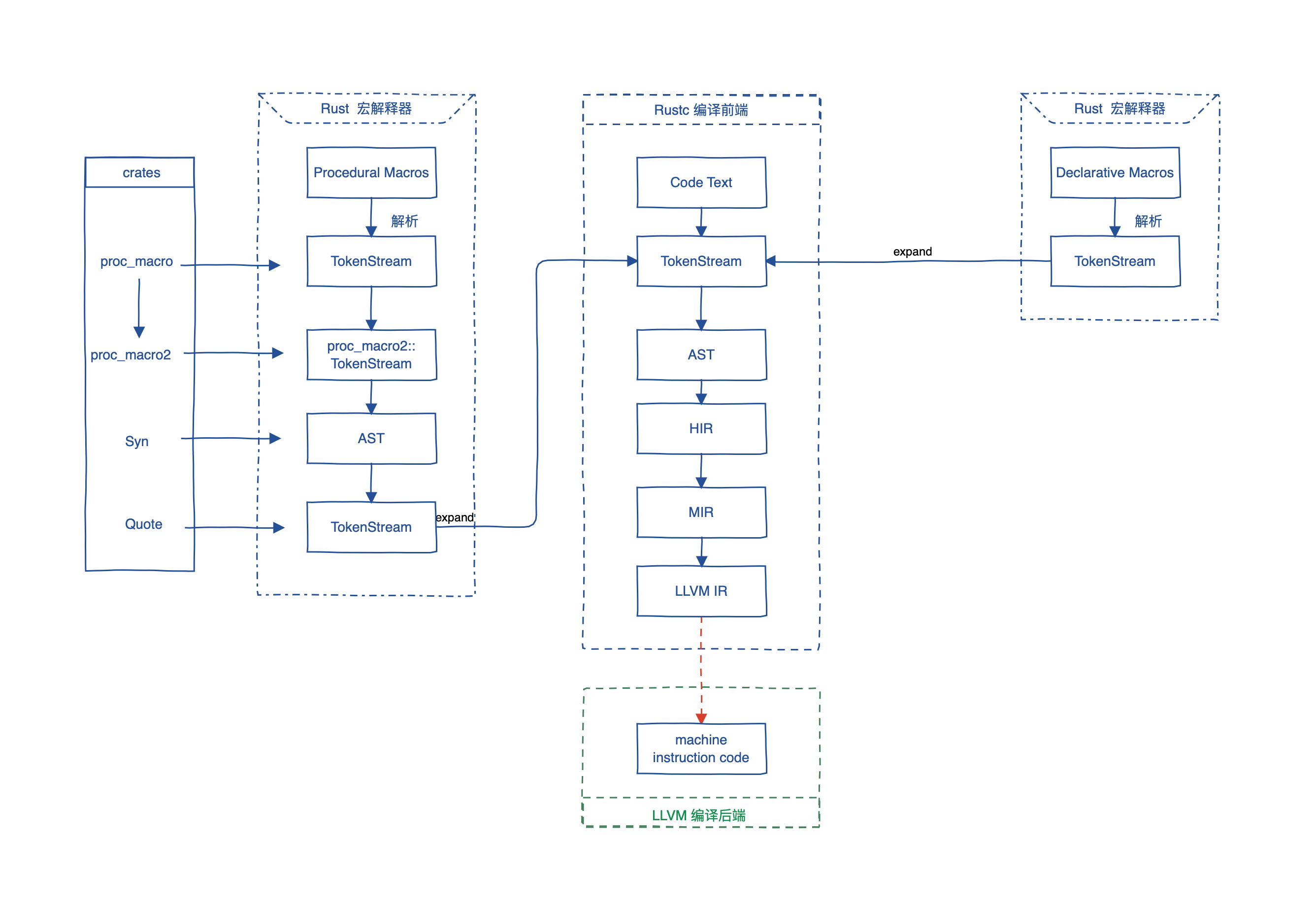
Rust 编译器执行过程
- rustc 命令执行编译
- rustc_driver 来解析命令行参数,相关编译配置被记录于 rustc_interface::Config
- rustc_lexer 用于词法解析,将源代码文本输出为 词条流 (Token Stream)
- rustc_parse 为编译过程下一阶段做准备。包含了词法分析的一部分,通过 内置的 StringBuffer 结构体对文本字符串进行验证,以及将字符串进行符号(Symbol)化。符号化是一种叫做 String interning 的技术,将字符串的值存储一份不可变的副本。
- rustc_parse 另一部分就是语法解析,使用递归下降(自顶向下)方法进行语法分析,将 词条流转换为 抽象语法树(AST)。入口点是 rustc_parse::parser::Parser 结构体的 Parser::parse_crate_mod()和Parser::parse_mod() 关联方法。外部模块解析入口点是rustc_expand::module::parse_external_mod。宏解析器入口点是Parser::parse_nonterminal()。
- 宏展开、AST验证、名称解析,以及 early lint 发生在编译过程的词法分析和语法分析阶段。
- 此后,将 AST转为HIR, 使用HIR 进行 类型推断](https://rustc-dev-guide.rust-lang.org/type-inference.html)(自动检测表达式类型的过程)、特质求解(将impl与对特质的每个引用配对的过程)和类型检查(转换类型的过程)。
- 随后,将HIR降级到中级中级代表 (MIR)。在此过程中,也构建了 THIR,这是一个更加脱糖的HIR。THIR (Typed HIR) 用于模式和穷举检查。转换成MIR 也比HIR 更方便。
- MIR 用于借用检查,它基本上是一个控制流图 (CFG)。此外 , MIR 还用于 优化、增量编译、Unsafe Rust UB 检查等。
最后,进行 代码生成 (Codegen)。将 MIR 转换为 LLVM IR,然后将LLVM IR传递给LLVM 生成目标机器代码。
另一件需要注意的事情是编译器中的许多值都是intern 的。这是一种性能和内存优化,我们在称为Arena的特殊分配器中分配值。
在 Rust 编译器中,上面说的过程主要步骤都被组织成一堆相互调用的查询。
Rust 编译器使用的是 查询系统(Query System),而非大多数编译原理教科书那种遍历式编译器(基于遍历 的编译器架构 )。Rust 使用查询系统是为了实现 增量编译功能,即按需编译。
Rust 编译器最初并不是基于查询系统实现的,所以现在整个编译器还在改造为查询系统过程中,上面的整个编译过程都将被改造为基于查询系统。但是截至到 2021年 11月,目前仅是在HIR 到LLVM IR 这个过程是基于查询的。
编译器源码结构
Rust 语言项目本身由三个主要目录组成:
- compiler/,包含源代码rustc。它由许多 crate 组成,这些 crate 共同构成了编译器。
- library/,包含标准库 ( core, alloc, std, proc_macro, test) 以及 Rust 运行时 ( backtrace, rtstartup, lang_start)。
- src/ ,包含 rustdoc、clippy、cargo、构建系统、语言文档等的源代码。
该compiler/包装箱所有名称以rustc_*。这些是大约 50 个相互依存的crate的集合,大小不等。还有rustc crate 是实际的二进制文件(即 main函数);除了调用rustc_driver crate之外,它实际上并没有做任何事情。
Rust 编译器之所以区分这么多 crate ,主要是以下两个因素考虑:
- 便于组织代码。编译器是一个巨大的代码库,拆分为多个 crate,更利于组织。
- 加速编译时间。多个 crate 有利于增量和并行编译。
但是因为 查询系统是在 rustc_middle 中定义的,而其他很多 crate 都依赖于它,而它又很大,导致编译时间很长。但是将其拆分的工作又没那么简单。
整个编译器 依赖树的顶部是rustc_interface和 rustc_driver crate。rustc_interface是围绕查询系统的未稳定包装器,有助于驱动编译的各个阶段。
查询:按需驱动编译
什么叫查询?比如有一个查询叫 type_of(def_id),只要给定某个Item 的 def-id (标识符定义的索引值 rustc_middle/src/hir/def_id.rs ),就可以得到该Item的类型。查询执行是被缓存的,这也是增量编译的机制。
复制
但是,如果查询 不在缓存中,则编译器将尝试找到合适的提供程序(provider)。提供程序是一个已定义并链接到编译器某处的函数,该函数包含用于计算查询结果的代码。
由 Rust 编译器的查询系统还衍生出一个通用的按需增量计算框架 Salsa。你可以通过 Salsa BOOK 进一步了解查询系统工作机制。
源码阅读:名称解析组件 rustc_resolve
经过前面关于 Rust 编译器架构背景相关了解,我们知道, rustc_resolve 名称解析是发生在 语法分析阶段,为生成最终 抽象语法树而服务,所以,这个库并没有使用到 查询系统。
crate 的模块在这里构建,宏的路径、模块导入、表达式、类型、模式、标签(label)和生命周期 都是在这里解析的
类型相关的名称解析(方法、字段、关联项)发生在rustc_typeck 上。