指针(pointer)是一个包含内存地址的变量的通用概念。这个地址引用,或“指向”(points at)一些其他数据。Rust 中最常见的指针是引用(reference)。引用以 & 符号为标志并借用了他们所指向的值。除了引用数据它们没有任何其他特殊功能。它们也没有任何额外开销,所以应用的最多。
另一方面,智能指针(smart pointers)是一类数据结构,他们的表现类似指针,但是也拥有额外的元数据和功能。智能指针的概念并不为 Rust 所独有;其起源于 C++ 并存在于其他语言中。Rust 标准库中不同的智能指针提供了多于引用的额外功能。我们将会探索的一个例子便是引用计数(reference counting)智能指针类型,其允许数据有多个所有者。引用计数智能指针记录总共有多少个所有者,并当没有任何所有者时负责清理数据。
在 Rust 中,普通引用和智能指针的一个额外的区别是引用是一类只借用数据的指针;相反大部分情况,智能指针拥有他们指向的数据。
实际上之前已经出现过一些智能指针,String 和 Vec<T> 。虽然当时我们并不这么称呼它们。这些类型都属于智能指针因为它们拥有一些数据并允许你修改它们。它们也带有元数据(比如他们的容量)和额外的功能或保证(String 的数据总是有效的 UTF-8 编码)。
智能指针通常使用结构体实现。智能指针区别于常规结构体的显著特性在于其实现了 Deref 和 Drop trait。Deref trait 允许智能指针结构体实例表现的像引用一样,这样就可以编写既用于引用、又用于智能指针的代码。Drop trait 允许我们自定义当智能指针离开作用域时运行的代码。并且会讨论这些 trait 以及为什么对于智能指针来说他们很重要。
考虑到智能指针是一个在 Rust 经常被使用的通用设计模式,我们并不会覆盖所有现存的智能指针。很多库都有自己的智能指针而你也可以编写属于你自己的智能指针。这里将会讲到的是来自标准库中最常用的一些:
Box<T>,用于在堆上分配值Rc<T>,一个引用计数类型,其数据可以有多个所有者Ref<T>和RefMut<T>,通过RefCell<T>访问,RefCell<T>是一个在运行时而不是在编译时执行借用规则的类型。
同时我们会涉及内部可变性(interior mutability)模式,这时不可变类型暴露出改变其内部值的API。我们也会讨论引用循环(reference cycles)会如何泄露内存,以及如何避免。
一、Box 在堆上存储数据,并且可确定大小
最简单直接的智能指针是 box,其类型是 Box<T> 。 box 允许你将一个值放在堆上而不是栈上。留在栈上的则是指向堆数据的指针。
除了数据被储存在堆上而不是栈上之外,box没有性能损失,不过也没有很多额外的功能。他们多用于如下场景:
- 当有一个在编译时未知大小的类型,而又想要在需要确切大小的上下文中使用这个类型值的时候
- 当有大量数据并希望在确保数据不被拷贝的情况下转移所有权的时候
- 当希望拥有一个值并只关心它的类型是否实现了特定
trait而不是其具体类型的时候
我们将在本部分的余下内容中展示第一种应用场景。在第二种情况中,转移大量数据的所有权可能会花费很长的时间,因为数据在栈上进行了拷贝。为了改善这种情况下的性能,可以通过 box 将这些数据储存在堆上。接着,只有少量的指针数据在栈上被拷贝。第三种情况被称为 trait 对象(trait object)。
使用 Box 在堆上储存数据
在开始 Box<T> 的用例之前,让我们熟悉一下语法和如何与储存在 Box<T> 中的值交互。
使用 box 在堆上储存一个 i32 :fn main() {
let b = Box::new(5);
println!("b = {}", b);
}
这里定义了变量 b ,其值是一个指向被分配在堆上的值 5 的 Box 。这个程序会打印出 b = 5 ;在这个例子中,我们可以像数据是储存在栈上的那样访问 box 中的数据。正如任何拥有数据所有权的值那样,当像 b 这样的 box 在 main 的末尾离开作用域时,它将被释放。这个释放过程作用于 box 本身(位于栈上)和它所指向的数据(位于堆上)。
将一个单独的值存放在堆上并不是很有意义。
box 允许创建递归类型
Rust 需要在编译时知道类型占用多少空间。一种无法在编译时知道大小的类型是递归类型(recursive type),其值的一部分可以是相同类型的另一个值。这种值的嵌套理论上可以无限的进行下去,所以 Rust 不知道递归类型需要多少空间。不过 box 有一个已知的大小,所以通过在循环类型定义中插入box,就可以创建递归类型了。
让我们探索一下 cons list,一个函数式编程语言中的常见类型,来展示这个(递归类型)概念。除了递归之外,我们将要定义的 cons list 类型是很直白的,所以这个例子中的概念在任何遇到更为复杂的涉及到递归类型的场景时都很实用。
cons list
cons list 是一个来源于 Lisp 编程语言及其方言的数据结构。在 Lisp 中,cons 函数(“construct function” 的缩写)利用两个参数来构造一个新的列表,他们通常是一个单独的值和另一个列表。
cons 函数的概念涉及到更常见的函数式编程术语;“将 x 与 y 连接” 通常意味着构建一个新的容器而将 x 的元素放在新容器的开头,其后则是容器 y 的元素。
cons list 的每一项都包含两个元素:当前项的值和下一项。其最后一项值包含一个叫做 Nil 的值且没有下一项。cons list 通过递归调用 cons 函数产生。代表递归的终止条件(base case)的规范名称是 Nil,它宣布列表的终止。
注意虽然函数式编程语言经常使用 cons list,但是它并不是一个 Rust 中常见的类型。大部分在 Rust 中需要列表的时候,Vec<T> 是一个更好的选择。其他更为复杂的递归数据类型确实在 Rust 的很多场景中很有用,不过通过以 cons list 作为开始,我们可以探索如何使用 box 毫不费力的定义一个递归数据类型。
包含一个 cons list 的枚举定义。注意这还不能编译因为这个类型没有已知的大小,之后我们会展示:enum List {
Cons(i32, List),
Nil,
}
注意:出于示例的需要我们选择实现一个只存放 i32 值的 cons list。也可以用泛型实现它
使用这个 cons list 来储存列表 1, 2, 3 。use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}
第一个 Cons 储存了 1 和另一个 List 值。这个 List 是另一个包含 2 的 Cons 值和下一个 List 值。接着又有另一个存放了 3 的 Cons 值和最后一个值为 Nil 的 List ,非递归成员代表了列表的结尾。
如果尝试编译上面的代码,会得到下面错误:$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ recursive type has infinite size
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to make `List` representable
|
2 | Cons(i32, Box<List>),
| ^^^^ ^
error[E0391]: cycle detected when computing drop-check constraints for `List`
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which again requires computing drop-check constraints for `List`, completing the cycle
= note: cycle used when computing dropck types for `Canonical { max_universe: U0, variables: [], value: ParamEnvAnd { param_env: ParamEnv { caller_bounds: [], reveal: UserFacing }, value: List } }`
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` due to 2 previous errors
这个错误表明这个类型“有无限的大小”。其原因是 List 的一个成员被定义为是递归的:它直接存放了另一个相同类型的值。这意味着 Rust 无法计算为了存放 List 值到底需要多少空间。让我们一点一点来看: 首先了解一下 Rust 如何决定需要多少空间来存放一个非递归类型。
计算非递归类型的大小
当 Rust 需要知道要为 Message 值分配多少空间时,它可以检查每一个成员并发现 Message::Quit 并不需要任何空间,Message::Move 需要足够储存两个 i32 值的空间,依此类推。因此, Message 值所需的空间等于储存其最大成员的空间大小。enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
与此相对当 Rust 编译器检查像cons中的 List 这样的递归类型时会发生什么呢。编译器尝试计算出储存一个 List 枚举需要多少内存,并开始检查 Cons 成员,那么 Cons 需要的空间等于 i32 的大小加上 List 的大小。为了计算 List 需要多少内存,它检查其成员,从 Cons 成员开始。 Cons 成员储存了一个 i32 值和一个 List 值,这样的计算将无限进行下去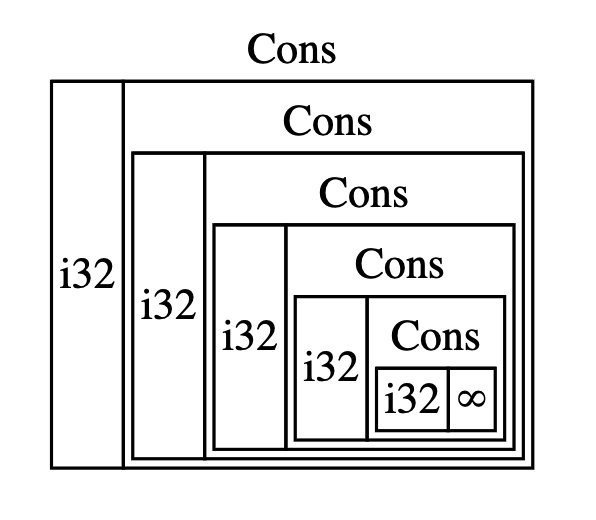
使用 Box 给递归类型一个已知的大小
Rust 无法计算出要为定义为递归的类型分配多少空间,所以编译器给出了错误。这个错误也包括了有用的建议:help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to make `List` representable
|
2 | Cons(i32, Box<List>),
| ^^^^ ^
在建议中,“indirection” 意味着不同于直接储存一个值,我们将间接的储存一个指向值的指针。
因为 Box<T> 是一个指针,我们总是知道它需要多少空间:指针的大小并不会根据其指向的数据量而改变。这意味着可以将 Box 放入 Cons 成员中而不是直接存放另一个 List 值。Box 会指向另一个位于堆上的 List 值,而不是存放在 Cons 成员中。从概念上讲,我们仍然有一个通过在其中 “存放” 其他列表创建的列表,不过现在实现这个概念的方式更像是一个项挨着另一项,而不是一项包含另一项。
|
Cons 成员将会需要一个 i32 的大小加上储存 box 指针数据的空间。 Nil 成员不储存值,所以它比 Cons 成员需要更少的空间。现在我们知道了任何 List 值最多需要一个 i32 加上 box 指针数据的大小。通过使用 box ,打破了这无限递归的连锁,这样编译器就能够计算出储存 List 值需要的大小了。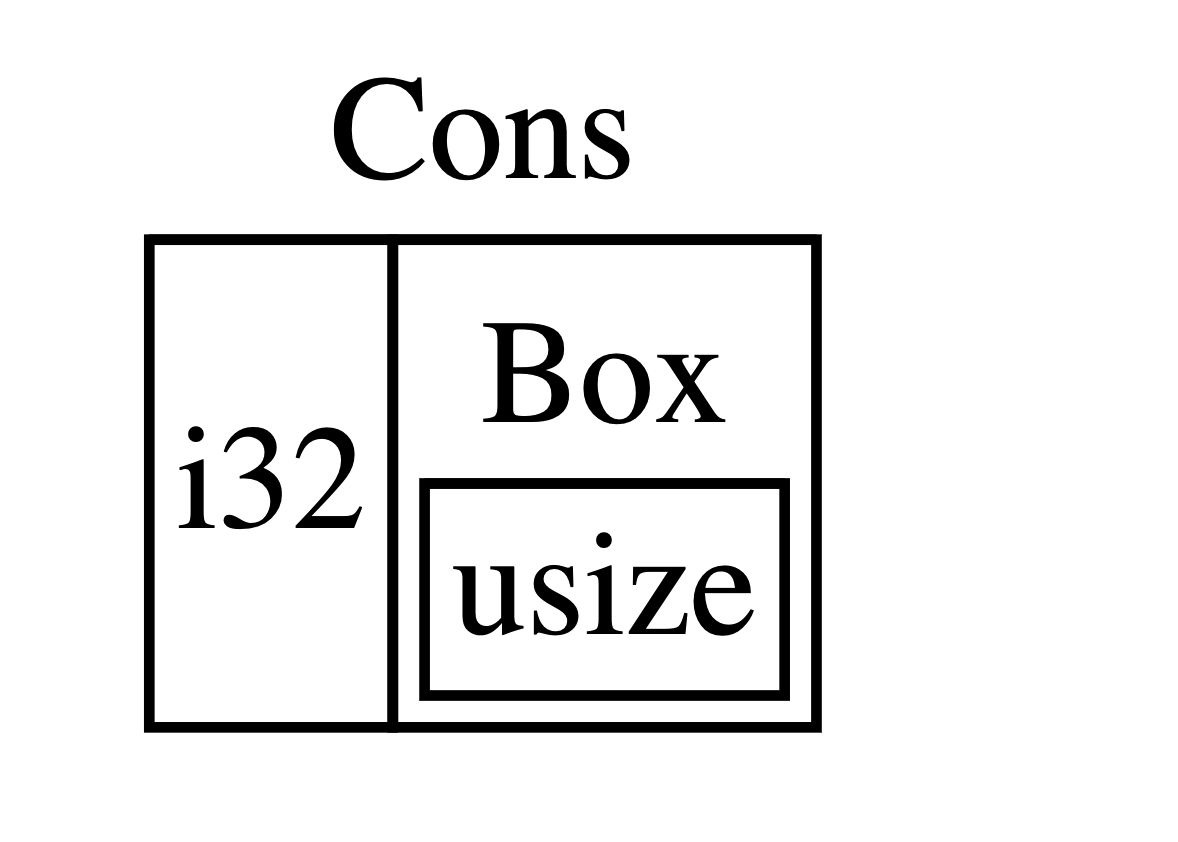
box 只提供了间接存储和堆分配;他们并没有任何其他特殊的功能,比如我们将会见到的其他智能指针。他们也没有这些特殊功能带来的性能损失,所以他们可以用于像 cons list 这样间接存储是唯一所需功能的场景。
Box<T> 类型是一个智能指针,因为它实现了 Deref trait,它允许 Box<T> 值被当作引用对待。当 Box<T> 值离开作用域时,由于 Box<T> 类型 Drop trait 的实现,box 所指向的堆数据也会被清除。让我们更详细的探索一下这两个 trait。
二、通过 Deref trait 将智能指针当作常规引用处理
实现 Deref trait 允许我们重载解引用运算符(dereference operator) * (与乘法运算符或 glob 运算符相区别)。通过这种方式实现 Deref trait 的智能指针可以被当作常规引用来对待,可以编写操作引用的代码并用于智能指针。
让我们首先看看解引用运算符如何处理常规引用,接着尝试定义我们自己的类似 Box<T> 的类型并看看为何解引用运算符不能像引用一样工作。我们会探索如何实现 Deref trait 使得智能指针以类似引用的方式工作变为可能。最后,我们会讨论 Rust 的 Deref 强制转换(deref coercions)功能以及它是如何处理引用或智能指针的。
我们将要构建的 MyBox
类型与真正的 Box 有一个很大的区别:我们的版本不会在堆上储存数据。这个例子重点关注 Deref,所以其数据实际存放在何处,相比其类似指针的行为来说不算重要。
通过 * 追踪指针的值
常规引用是一个指针类型,一种理解指针的方式是将其看成指向储存在其他某处值的箭头。创建了一个 i32 值的引用接着使用解引用运算符来跟踪所引用的数据:fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}
变量 x 存放了一个 i32 值 5。y 等于 x 的一个引用。可以断言 x 等于 5。然而, 如果希望对 y 的值做出断言,必须使用 *y 来追踪引用所指向的值(也就是解引用)。一旦解引用了 y ,就可以访问 y 所指向的整型值并可以与 5 做比较。
相反如果尝试编写 assert_eq!(5, y);,则会得到如下编译错误:$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` due to previous error
不允许比较数字的引用与数字,因为它们是不同的类型。必须使用 * 追踪引用所指向的值。
像引用一样使用 Box
可以重写上面的代码来使用 Box<T> 而不是引用,同时借引用运算符也一样能工作fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}
主要不同的地方就是将 y 设置为一个指向 x 值拷贝的 box 实例,而不是指向 x 值的引用。在最后的断言中,可以使用解引用运算符以 y 为引用时相同的方式追踪 box 的指针。
自定义智能指针
为了体会默认智能指针的行为不同于引用,让我们创建一个类似于标准库提供的 Box<T> 类型的智能指针。接着会学习如何增加使用解引用运算符的功能。
从根本上说, Box<T> 被定义为包含一个元素的元组结构体,所以下面以相同的方式定义了 MyBox<T> 类型。我们还定义了 new 函数来对应定义于 Box<T> 的 new 函数:struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
这里定义了一个结构体 MyBox 并声明了一个泛型 T ,因为我们希望其可以存放任何类型的值。 MyBox 是一个包含 T 类型元素的元组结构体。 MyBox::new 函数获取一个 T 类型的参数并返回一个存放传入值的 MyBox 实例。
代码不能编译,因为 Rust 不知道如何解引用 MyBox :fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}
得到的编译错误是:$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` due to previous errorMyBox<T> 类型不能解引用我们并没有为其实现这个功能。为了启用 * 运算符的解引用功能,可以实现 Deref trait。
实现 Deref trait 定义如何像引用一样对待某类型
为了实现 trait,需要提供 trait 所需的方法实现。 Deref trait,由标准库提供,要求实现名为 deref 的方法,其借用 self 并返回一个内部数据的引用。use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}type Target = T; 语法定义了用于此 trait 的关联类型。关联类型是一个稍有不同的定义泛型参数的方式,现在还无需过多的担心他。
deref 方法体中写入了 &self.0 ,这样 deref 返回了我希望通过 * 运算符访问的值的引用。
没有 Deref trait 的话,编译器只会解引用 & 引用类型。 Deref trait 的 deref 方法为编译器提供了获取任何实现了 Deref 的类型值的能力,为了获取其知道如何解引用的 & 引用编译器可以调用 deref 方法。
当我们输入 *y 时,Rust 事实上在底层运行了如下代码:*(y.deref())
Rust 将 * 运算符替换为 deref 方法调用和一个普通解引用,如此我们便无需担心是否需要调用 deref 方法。Rust 的这个功能让我们可以编写同时处理常规引用或实现了 Deref 的类型的代码。
deref 方法返回值的引用,以及 *(y.deref()) 括号外边的普通解引用仍为必须的原因在于所有权。如果 deref 方法直接返回值而不是值的引用,其值(的所有权)将被移出 self 。 在这里以及大部分使用解引用运算符的情况下我们并不希望获取 MyBox<T> 内部值的所有权。
注意,每次当我们在代码中使用 * 时, * 运算符都被替换成了先调用 deref 方法再接着使用 * 解引用的操作,且只会发生一次,不会对 * 操作符无限递归替换,解引用出上面 i32 类型的值就停止了。
函数和方法的隐式解引用强制多态
Deref 强制转换(deref coercions)是 Rust 在函数或方法传参上的一种便利。Deref 强制转换只能作用于实现了 Deref trait 的类型。Deref 强制转换将这样一个类型的引用转换为另一个类型的引用。例如,Deref 强制转换可以将 &String 转换为 &str,因为 String 实现了 Deref trait 因此可以返回 &str。当这种特定类型的引用作为实参传递给和形参类型不同的函数或方法时,Deref 强制转换将自动发生。这时会有一系列的 deref 方法被调用,把我们提供的类型转换成了参数所需的类型。
解引用强制多态的加入使得 Rust 程序员编写函数和方法调用时无需增加过多显式使用 & 和 * 的引用和解引用。这个功能也使得我们可以编写更多同时作用于引用或智能指针的代码。fn hello(name: &str) {
println!("Hello, {}!", name);
}
可以使用字符串 slice 作为参数调用 hello 函数,比如 hello(“Rust”); 。解引用强制多态使得用 MyBox<String> 类型值的引用调用 hello 成为可能。fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}
这里使用 &m 调用 hello 函数,其为 MyBox<String> 值的引用。MyBox<T> 上实现了 Deref trait,Rust可以通过 deref 调用将 &MyBox<String> 变为 &String 。标准库中提供了 String 上的 Deref 实现,其会返回字符串 slice,这可以在 Deref 的 API 文档中看到。Rust 再次调用 deref 将 &String 变为 &str ,这就符合 hello 函数的定义了。
如果 Rust 没有实现解引用强制多态,为了使用 &MyBox<String>类型的值调用 hello ,则不得不编写如下代码替换fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}(*m) 将 MyBox<String> 解引用为 String 。接着 & 和 [..] 获取了整个 String 的字符串 slice 来匹配 hello 的签名。没有解引用强制多态所有这些符号混在一起将更难以读写和理解。解引用强制多态使得 Rust 自动的帮我们处理这些转换。
当所涉及到的类型定义了 Deref trait,Rust 会分析这些类型并使用任意多次 Deref::deref 调用以获得匹配参数的类型。这些解析都发生在编译时,所以利用解引用强制多态并没有运行时损耗!
解引用强制多态如何与可变性交互
类似于如何使用 Deref trait 重载不可变引用的 * 运算符,Rust 提供了 DerefMut trait 用于重载可变引用的 * 运算符。
Rust 在发现类型和 trait 实现满足三种情况时会进行解引用强制多态:
- 当
T: Deref<Target=U>时从&T到&U。 - 当
T: DerefMut<Target=U>时从&mut T到&mut U。 - 当
T: Deref<Target=U>时从&mut T到&U。
头两个情况除了可变性之外是相同的:第一种情况表明如果有一个 &T ,而 T 实现了返回 U 类型的 Deref ,则可以直接得到 &U 。第二种情况表明对于可变引用也有着相同的行为。
最后一个情况有些微妙:Rust 也会将可变引用强转为不可变引用。但是反之是 不可能 的: 不可变引用永远也不能强转为可变引用。因为根据借用规则,如果有一个可变引用,其必须是这些数据的唯一引用(否则程序将无法编译)。将一个可变引用转换为不可变引用永远也不会打破借用规则。将不可变引用转换为可变引用则需要数据只能有一个不可变引用,而借用规则无法保证这一点。因此,Rust 无法假设将不可变引用转换为可变引用是可能的。
三、Drop Trait 运行清理代码
对于智能指针模式来说另一个重要的 trait 是 Drop 。 Drop 允许我们在值要离开作用域时执行一些代码。可以为任何类型提供 Drop trait 的实现,同时所指定的代码被用于释放类似于文件或网络连接的资源。我们在智能指针上下文中讨论 Drop 是因为其功能几乎总是用于实现智能指针。例如, Box<T> 自定义了 Drop 用来释放 box 所指向的堆空间。
在其他一些语言中,我们不得不记住在每次使用完智能指针实例后调用清理内存或资源的代码。如果忘记的话,运行代码的系统可能会因为负荷过重而崩溃。在 Rust 中,可以指定一些代码应该在值离开作用域时被执行,而编译器会自动插入这些代码。
这意味着无需记住在所有处理完这些类型实例后调用清理代码,而仍然不会泄露资源!
指定在值离开作用域时应该执行的代码的方式是实现 Drop trait。 Drop trait 要求实现一个叫做 drop 的方法,它获取一个 self 的可变引用。为了能够看出 Rust 何时调用 drop ,让我们暂时使用 println! 语句实现 drop 。struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created.");
}Drop trait 包含在 prelude 中,所以无需导入它。我们在 CustomSmartPointer 上实现了Drop trait,并提供了一个调用 println! 的 drop 方法实现。 drop 函数体是放置任何当类型实例离开作用域时期望运行的逻辑的地方。这里选择打印一些文本以展示 Rust 合适调用drop 。
在 main 中,新建了一个 CustomSmartPointer 实例并打印出了 CustomSmartPointer created. 。在 main 的结尾, CustomSmartPointer 的实例会离开作用域,而 Rust 会调用放置于 drop 方法中的代码,打印出最后的信息。注意无需显示调用 drop 方法:
当运行这个程序,会出现如下输出:$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created.
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
当实例离开作用域 Rust 会自动调用 drop ,并调用我们指定的代码。变量以被创创建时相反的顺序被丢弃,所以 d 在 c 之前被丢弃。这刚好给了我们一个 drop 方法如何工作的可视化指导,不过通常需要指定类型所需执行的清理代码而不是打印信息。
通过 std::mem::drop 提早丢弃值
不幸的是,我们并不能直截了当的禁用 drop 这个功能。通常也不需要禁用 drop ;整个 Drop trait 存在的意义在于其是自动处理的。然而,有时你可能需要提早清理某个值。一个例子是当使用智能指针管理锁时;你可能希望强制运行 drop 方法来释放锁以便作用域中的其他代码可以获取锁。Rust 并不允许我们主动调用 Drop trait 的 drop 方法;当我们希望在作用域结束之前就强制释放变量的话,我们应该使用的是由标准库提供的 std::mem::drop。fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
c.drop();
println!("CustomSmartPointer dropped before the end of main.");
}
如果尝试编译代码会得到如下错误:$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| --^^^^--
| | |
| | explicit destructor calls not allowed
| help: consider using `drop` function: `drop(c)`
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` due to previous error
错误信息表明不允许显式调用 drop 。错误信息使用了术语 析构函数(destructor),这是一个清理实例的函数的通用编程概念。析构函数 对应创建实例的 构造函数。Rust 中的 drop 函数就是这么一个析构函数。
Rust 不允许我们显式调用 drop 因为 Rust 仍然会在 main 的结尾对值自动调用 drop ,这会导致一个 double free 错误,因为 Rust 会尝试清理相同的值两次。
因为不能禁用当值离开作用域时自动插入的 drop ,并且不能显示调用 drop ,如果我们需要提早清理值,可以使用 std::mem::drop 函数。
std::mem::drop 函数不同于 Drop trait 中的 drop 方法。可以通过传递希望提早强制丢弃的值作为参数。 std::mem::drop 位于 preludefn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
drop(c);
println!("CustomSmartPointer dropped before the end of main.");
}
运行这段代码会打印出如下:$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main.Dropping CustomSmartPointer with data some data! 出现在 CustomSmartPointer created. 和 CustomSmartPointer dropped before the end of main. 之间,表明了 drop 方法被调用了并在此丢弃了 c 。
Drop trait 实现中指定的代码可以用于许多方面来使得清理变得方便和安全:比如可以用其创 建我们自己的内存分配器! 通过 Drop trait 和 Rust 所有权系统,你无需担心之后清理代码, Rust 会自动考虑这些问题。
我们也无需担心意外的清理掉仍在使用的值,这会造成编译器错误:所有权系统确保引用总是有效的,也会确保 drop 只会在值不再被使用时被调用一次。
使用 Drop trait 实现指定的代码在很多方面都使得清理值变得方便和安全:比如可以使用它来创建我们自己的内存分配器!通过 Drop trait 和 Rust 所有权系统,就无需担心之后清理代码,因为 Rust 会自动考虑这些问题。如果代码在值仍被使用时就清理它会出现编译错误,因为所有权系统确保了引用总是有效的,这也就保证了 drop 只会在值不再被使用时被调用一次。
四、Rc 引用计数智能指针
大部分情况下所有权是非常明确的:可以准确的知道哪个变量拥有某个值。然而,有些情况单个值可能会有多个所有者。例如,在图数据结构中,多个边可能指向相同的结点,而这个结点从概念上讲为所有指向它的边所拥有。结点直到没有任何边指向它之前都不应该被清理。
为了启用多所有权,Rust 有一个叫做 Rc<T> 的类型。其名称为 引用计数(reference counting) 的缩写。引用计数意味着记录一个值引用的数量来知晓这个值是否仍在被使用。如果某个值有零个引用,就代表没有任何有效引用并可以被清理。
可以将其想象为客厅中的电视。当一个人进来看电视时,他打开电视。其他人也可以进来看电视。当最后一个人离开房间时,他关掉电视因为它不再被使用了。如果某人在其他人还在看的时候就关掉了电视,正在看电视的人肯定会抓狂的!
Rc<T> 用于当我们希望在堆上分配一些内存供程序的多个部分读取,而且无法在编译时确定程序的那一部分会最后结束使用它的时候。如果确实知道哪部分会结束使用的话,就可以令其成为数据的所有者同时正常的所有权规则就可以在编译时生效。
注意 Rc<T> 只能用于单线程场景。
使用 Rc 共享数据
Box<T> 定义 cons list 的例子。这一次,我们希望创建两个共享第三个列表所有权的列表,其概念将会看起来如下所示: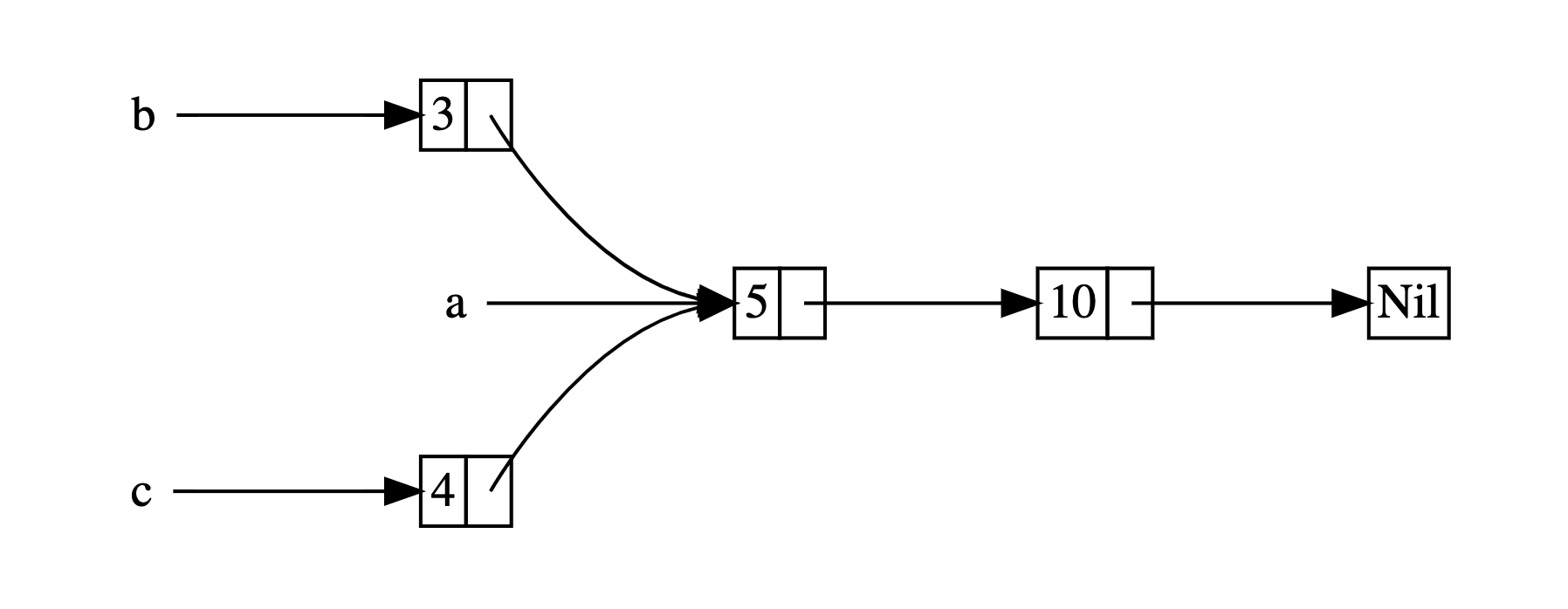
列表 a 包含5之后是10,之后是另两个列表: b 从3开始而 c 从4开始。 b 和 c 会 接上包含 5 和 10 的列表 a 。换句话说,这两个列表会尝试共享第一个列表所包含的 5 和 10。
尝试使用 Box<T> 定义的 List 并实现不能工作,enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}
编译会得出如下错误:$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` due to previous error
Cons 成员拥有其储存的数据,所以当创建 b 列表时, a 被移动进了 b 这样 b 就拥有了 a 。接着当再次尝使用 a 创建 c 时,这不被允许因为 a 的所有权已经被移动。
可以改变 Cons 的定义来存放一个引用,不过接着必须指定生命周期参数。通过指定生命周期参数,表明列表中的每一个元素都至少与列表本身存在的一样久。例如,借用检查器不会允许 let a = Cons(10, &Nil); 编译,因为临时值 Nil 会在 a 获取其引用之前就被丢弃 了。
相反,我们修改 List 的定义为使用 Rc<T> 代替 Box<T> 。现在每一个 Cons 变量都包含一个值和一个指向 List 的 Rc 。当创建 b 时,不同于获取 a 的所有权,这里会克隆 a 所包含的 Rc ,这会将引用计数从1增加到2并允许 a 和 b 共享 Rc 中数据的所有权。创建 c 时也会克隆 a ,这会将引用计数从 2 增加为 3。每次调用 Rc::clone , Rc 中数据的引用计数都会增加,直到有零个引用之前其数据都不会被清理:enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}
需要使用 use 语句将 Rc<T> 引入作用域,因为它不在 prelude 中。在 main 中创建了存放 5 和 10 的列表并将其存放在 a 的新的 Rc<List> 中。接着当创建 b 和 c 时,调用 Rc::clone 函数并传递 a 中 Rc<List> 的引用作为参数。
也可以调用 a.clone() 而不是 Rc::clone(&a) ,不过在这里 Rust 的习惯是使用Rc::clone 。 Rc::clone 的实现并不像大部分类型的 clone 实现那样对所有数据进行深拷贝。 Rc::clone 只会增加引用计数,这并不会花费多少时间。深拷贝可能会花费很长时间, 所以通过使用 Rc::clone 进行引用计数,可以明显的区别可能会对运行时性能有巨大影响的深拷贝和不分配内存的对运行时性能影响相对较小的增加引用计数拷贝。
克隆 Rc 会增加引用计数
在程序中每个引用计数变化的点,会打印出引用计数,其值可以通过调用 Rc::strong_count 函数获得。后面的部分讨论避免引用循环时会解释为何这个函数叫做 strong_count 而不是 count 。fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}
这会打印出:$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
我们能够看到 a 中 Rc<List> 的初始引用计数为 1,接着每次调用 clone ,计数会增加 1。当 c 离开作用域时,计数减 1。不必像调用 Rc::clone 增加引用计数那样调用一个函数来减少计数; Drop trait 的实现当 Rc 值离开作用域时自动减少引用计数。
从这个例子我们所不能看到的是在 main 的结尾当 b 然后是 a 离开作用域时,此处计数会是 0,同时 Rc 被完全清理。使用 Rc 允许一个值有多个所有者,引用计数则确保只要任何所有者依然存在其值也保持有效。
Rc<T> 允许通过不可变引用来只读的在程序的多个部分共享数据。如果 Rc<T> 也允许多个可变引用,则会违反借用规则之一:相同位置的多个可变借用可能造成数据竞争和不一致。不过可以修改数据是非常有用的!在下一部分,我们将讨论内部可变性模式和RefCell<T> 类型,它可以与 Rc<T> 结合使用来处理不可变性的限制。
五、RefCell 和内部可变性模式
内部可变性(Interior mutability)是 Rust 中的一个设计模式,它允许你即使在有不可变引用时改变数据,这通常是借用规则所不允许的。为此,该模式在数据结构中使用 unsafe 代码 来模糊 Rust 通常的可变性和借用规则。当可以确保代码在运行时会遵守借用规则,即使编译器不能保证的情况,可以选择使用那些运用内部可变性模式的类型。所涉及的 unsafe 代码将被封装进安全的 API 中,而外部类型仍然是不可变的。
让我们通过遵循内部可变性模式的 RefCell<T> 类型来开始探索。
通过 RefCell 在运行时检查借用规则
不同于 Rc<T> , RefCell<T> 代表其数据的唯一的所有权。那么是什么让 RefCell<T> 不同于像 Box<T> 这样的类型呢?
借用规则:
- 在任意给定时间,只能拥有如下中的一个:
- 一个可变引用。
- 任意数量的不可变引用。
- 在任意给定时间,只能拥有如下中的一个:
- 引用必须总是有效的。
对于引用和 Box<T> ,借用规则的不可变性作用于编译时。对于 RefCell<T> ,这些不可变性作用于 运行时。对于引用,如果违反这些规则,会得到一个编译错误。而对于 RefCell<T> , 违反这些规则会 panic! 并退出。
在编译时检查借用规则的好处是这些错误将在开发过程的早期被捕获同时对没有运行时性能影响,因为所有的分析都提前完成了。为此,在编译时检查借用规则是大部分情况的最佳选择,这也正是其为何是 Rust 的默认行为。
相反在运行时检查借用规则的好处是特定内存安全的场景是允许的,而它们在编译时检查中是不允许的。静态分析,正如 Rust 编译器,是天生保守的。
因为一些分析是不可能的,如果 Rust 编译器不能通过所有权规则编译,它可能会拒绝一个正确的程序;从这种角度考虑它是保守的。如果 Rust 接受不正确的程序,那么人们也就不会相信 Rust 所做的保证了。然而,如果 Rust 拒绝正确的程序,会给程序员带来不便,但不会带来灾难。 RefCell<T> 正是用于当你确信代码遵守借用规则,而编译器不能理解和确定的时候。
类似于 Rc<T> , RefCell<T> 只能用于单线程场景。如果尝试在多线程上下文中使用 RefCell<T> ,会得到一个编译错误。
如下为选择 Box<T> , Rc<T> 或 RefCell<T> 的理由:
Rc<T>允许相同数据有多个所有者;Box<T>和RefCell<T>有单一所有者。Box<T>允许在编译时执行不可变(或可变)借用检查;Rc<T>仅允许在编译时执行不可变借用检查;RefCell<T>允许在运行时执行不可变(或可变)借用检查。- 因为
RefCell<T>允许在运行时执行可变借用检查,所以我们可以在即便RefCell<T>自身是不可变的情况下修改其内部的值。
最后一个理由便是指 内部可变性 模式。让我们看看何时内部可变性是有用的,并讨论这是如何成为可能的。
内部可变性:不可变值的可变借用
借用规则的一个推论是当有一个不可变值时,不能可变的借用它。例如,如下代码不能编译:fn main() {
let x = 5;
let y = &mut x;
}
如果尝试编译,会得到如下错误:$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
2 | let x = 5;
| - help: consider changing this to be mutable: `mut x`
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` due to previous error
然而,特定情况下,令一个值在其方法内部能够修改自身,而在其他代码中仍视为不可变,是很有用的。值方法外部的代码就不能修改其值了。RefCell<T> 是一个获得内部可变性的方法。RefCell<T> 并没有完全绕开借用规则,编译器中的借用检查器允许内部可变性并相应地在运行时检查借用规则。如果违反了这些规则,会出现 panic 而不是编译错误。
让我们通过一个实际的例子来探索何处可以使用 RefCell<T> 来修改不可变值并看看为何这么做是有意义的。
内部可变性的用例:mock 对象
测试替身(test double)是一个通用编程概念,它代表一个在测试中替代某个类型的类型。 mock 对象 是特定类型的测试替身,它们记录测试过程中发生了什么以便可以断言操作是正确的。
虽然 Rust 没有与其他语言中的对象完全相同的对象,Rust 也没有像其他语言那样在标准库中内建 mock 对象功能,不过我们确实可以创建一个与 mock 对象有着相同功能的结构体。
如下是一个我们想要测试的场景: 我们在编写一个记录某个值与最大值的差距的库,并根据当前值与最大值的差距来发送消息。例如,这个库可以用于记录用户所允许的 API 调用数量限额。
该库只提供记录与最大值的差距,以及何种情况发送什么消息的功能。使用此库的程序则期望提供实际发送消息的机制: 程序可以选择记录一条消息、发送 email、发送短信等等。库本身无需知道这些细节;只需实现其提供的 Messenger trait 即可。pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &T, max: usize) -> LimitTracker<T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
这些代码中一个重要部分是拥有一个方法 send 的 Messenger trait,其获取一个 self 的不可变引用和文本信息。这个 trait 是 mock 对象所需要实现的接口库,这样 mock 就能像一个真正的对象那样使用了。另一个重要的部分是我们需要测试 LimitTracker 的 set_value 方法的行为。可以改变传递的 value 参数的值,不过 set_value 并没有返回任何可供断言的值。也就是说,如果使用某个实现了 Messenger trait 的值和特定的 max 创建 LimitTracker,当传递不同 value 值时,消息发送者应被告知发送合适的消息。
我们所需的 mock 对象是,调用 send 并不实际发送 email 或消息,而是只记录信息被通知要发送了。可以新建一个 mock 对象实例,用其创建 LimitTracker,调用 LimitTracker 的 set_value 方法,然后检查 mock 对象是否有我们期望的消息。#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}
测试代码定义了一个 MockMessenger 结构体,其 sent_messages 字段为一个 String 值的 Vec 用来记录被告知发送的消息。我们还定义了一个关联函数 new 以便于新建从空消息列表开始的 MockMessenger 值。接着为 MockMessenger 实现 Messenger trait这样就可以为 LimitTracker 提供一个 MockMessenger 。在 send 方法的定义中,获取传入的消息作为参数并储存在 MockMessenger 的 sent_messages 列表中。
在测试中,我们测试了当 LimitTracker 被告知将 value 设置为超过 max 值 75% 的某个值。首先新建一个 MockMessenger ,其从空消息列表开始。接着新建一个 LimitTracker 并传递新建 MockMessenger 的引用和 max 值 100。我们使用值 80 调用 LimitTracker 的set_value 方法,这超过了 100 的 75%。接着断言 MockMessenger 中记录的消息列表应该有一条消息。
然而,这个测试是有问题的:$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
2 | fn send(&self, msg: &str);
| ----- help: consider changing that to be a mutable reference: `&mut self`
...
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` due to previous error
warning: build failed, waiting for other jobs to finish...
error: build failed
不能修改 MockMessenger 来记录消息,因为 send 方法获取 self 的不可变引用。我们也不能参考错误文本的建议使用 &mut self 替代,因为这样 send 的签名就不符合 Messenger trait 定义中的签名了(请随意尝试如此修改并看看会出现什么错误信息)。
这正是内部可变性的用武之地!我们将通过 RefCell 来储存 sent_messages ,然后 send 将能够修改 sent_messages 并储存消息。#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}
现在 sent_messages 字段的类型是 RefCell<Vec<String>> 而不是 Vec<String> 。在 new 函数中新建了一个 RefCell 示例替代空 vector。
对于 send 方法的实现,第一个参数仍为 self 的不可变借用,这是符合方法定义的。我们调用 self.sent_messages 中 RefCell 的 borrow_mut 方法来获取 RefCell 中值的可变引用,这是一个 vector。接着可以对 vector 的可变引用调用 push 以便记录测试过程中看到的消息。
最后必须做出的修改位于断言中: 为了看到其内部 vector 中有多少个项,需要调用 RefCell 的 borrow 以获取 vector 的不可变引用。
现在我们见识了如何使用 RefCell<T> ,让我们研究一下它怎样工作的!
RefCell 在运行时检查借用规则
当创建不可变和可变引用时,我们分别使用 & 和 &mut 语法。对于 RefCell<T> 来说,则是 borrow 和 borrow_mut 方法,这属于 RefCell<T> 安全 API 的一部分。 borrow 方法返回 Ref 类型的智能指针, borrow_mut 方法返回 RefMut 类型的智能指针。这两个类型都实现了 Deref 所以可以当作常规引用对待。
RefCell<T> 记录当前有多少个活动的 Ref 和 RefMut 智能指针。每次调用borrow , RefCell<T> 将活动的不可变借用计数加一。当 Ref 值离开作用域时,不可变借用计数减一。就像编译时借用规则一样, RefCell<T> 在任何时候只允许有多个不可变借用或一个可变借用。
如果我们尝试违反这些规则,相比引用时的编译时错误, RefCell<T> 的实现会在运行时 panic! 。impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
这里为 borrow_mut 返回的 RefMut 智能指针创建了 one_borrow 变量。接着用相同的方式 在变量 two_borrow 创建了另一个可变借用。这会在相同作用域中创建两个可变引用,这是不允许的,如果运行库的测试,编译时不会有任何错误,不过测试会失败:$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'main' panicked at 'already borrowed: BorrowMutError', src/lib.rs:60:53
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
可以看到代码 panic 和信息 already borrowed: BorrowMutError 。这也就是 RefCell<T> 如何在运行时处理违反借用规则的情况。
在运行时捕获借用错误而不是编译时意味着将会在开发过程的后期才会发现错误 ———— 甚至有可能发布到生产环境才发现。还会因为在运行时而不是编译时记录借用而导致少量的运行时性能错误。然而,使用 RefCell 使得在只允许不可变值的上下文中编写修改自身以记录消息的 mock 对象成为可能。虽然有取舍,但是我们可以选择使用 RefCell<T> 来获得比常规引用所能提供的更多的功能。
结合 Rc 和 RefCell 来拥有多个可变数据所有者
RefCell<T> 的一个常见用法是与 Rc<T> 结合。回忆一下 Rc<T> 允许对相同数据有多个所有者,不过只能提供数据的不可变访问。如果有一个储存了 RefCell<T> 的 Rc<T> 的话,就可以得到有多个所有者并且可以修改的值了!#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {:?}", a);
println!("b after = {:?}", b);
println!("c after = {:?}", c);
}
这里创建了一个 Rc<RefCell<i32> 实例并储存在变量 value 中以便之后直接访问。接着在 a 中用包含 value 的 Cons 成员创建了一个 List 。需要克隆 value 以便 a 和 value都能拥有其内部值 5 的所有权,而不是将所有权从 value 移动到 a 或者让 a 借用 value 。
我们将列表 a 封装进了 Rc<T> 这样当创建列表 b 和 c 时,他们都可以引用 a 。
一旦创建了列表 a 、 b 和 c ,我们将 value 的值加 10。为此对 value 调用了 borrow_mut ,这里使用了自定解引用功能来解引用 Rc<T> 以获取其内部的 RefCell<T> 值。 borrow_mut 方法返回 RefMut<T> 智能指针,可以对其使用解引用运算符并修改其内部值。
当我们打印出 a 、 b 和 c 时,可以看到他们都拥有修改后的值 15 而不是 5:$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
这是非常巧妙的! 通过使用 RefCell<T> ,我们可以拥有一个表面上不可变的 List ,不过可以使用 RefCell<T> 中提供内部可变性的方法来在需要时修改数据。 RefCell<T> 的运行时借用规则检查也确实保护我们免于出现数据竞争,而且我们也决定牺牲一些速度来换取数据结构的灵活性。
标准库中也有其他提供内部可变性的类型,比如 Cell<T> ,它有些类似( RefCell<T> )除了相比提供内部值的引用,其值被拷贝进和拷贝出 Cell<T> 。还有 Mutex<T> ,其提供线程间安全的内部可变性。
六、引用循环与内存泄漏
Rust 的内存安全性保证使其难以意外地制造永远也不会被清理的内存(被称为 内存泄漏(memory leak)),但并不是不可能。与在编译时拒绝数据竞争不同, Rust 并不保证完全地避免内存泄漏,这意味着内存泄漏在 Rust 被认为是内存安全的。这一点可以通过 Rc<T> 和 RefCell<T> 看出:创建引用循环的可能性是存在的。这会造成内存泄漏,因为每一项的引用计数永远也到不了 0,其值也永远不会被丢弃。
制造引用循环
让我们看看引用循环是如何发生的以及如何避免它。use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
现在 Cons 成员的第二个元素是 RefCell<Rc<List>> ,这意味着不同于之前那样能够修改 i32 的值,我们希望能够修改 Cons 成员所指向的 List 。这里还增加了一个 tail 方法来方便我们在有 Cons 成员的时候访问其第二项。
这些代码在 a 中 创建了一个列表,一个指向 a 中列表的 b 列表,接着修改 b 中的列表指向 a 中的列表,这会创建一个引用循环。在这个过程的多个位置有 println! 语句展示引用计数。fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle;
// it will overflow the stack
// println!("a next item = {:?}", a.tail());
}
这里在变量 a 中创建了一个 Rc<List> 实例来存放初值为 5, Nil 的 List 值。接着在变量 b 中创建了存放包含值 10 和指向列表 a 的 List 的另一个 Rc<List> 实例。
最后,修改 a 使其指向 b 而不是 Nil,这就创建了一个循环。为此需要使用 tail 方法获取 a 中 RefCell<Rc<List>> 的引用,并放入变量 link 中。接着使用 RefCell<Rc<List>> 的 borrow_mut 方法将其值从存放 Nil 的 Rc<List> 修改为 b 中的 Rc<List>。
如果保持最后的 println! 行注释并运行代码,会得到如下输出:$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
可以看到将列表 a 修改为指向 b 之后, a 和 b 中的 Rc<List> 实例的引用计数都是 2。在 main 的结尾,Rust 丢弃 b,这会 b Rc<List> 实例的引用计数从 2 减为 1。然而,b Rc<List> 不能被回收,因为其引用计数是 1 而不是 0。接下来 Rust 会丢弃 a 将 a Rc<List> 实例的引用计数从 2 减为 1。这个实例也不能被回收,因为 b Rc<List> 实例依然引用它,所以其引用计数是 1。这些列表的内存将永远保持未被回收的状态。引用循环: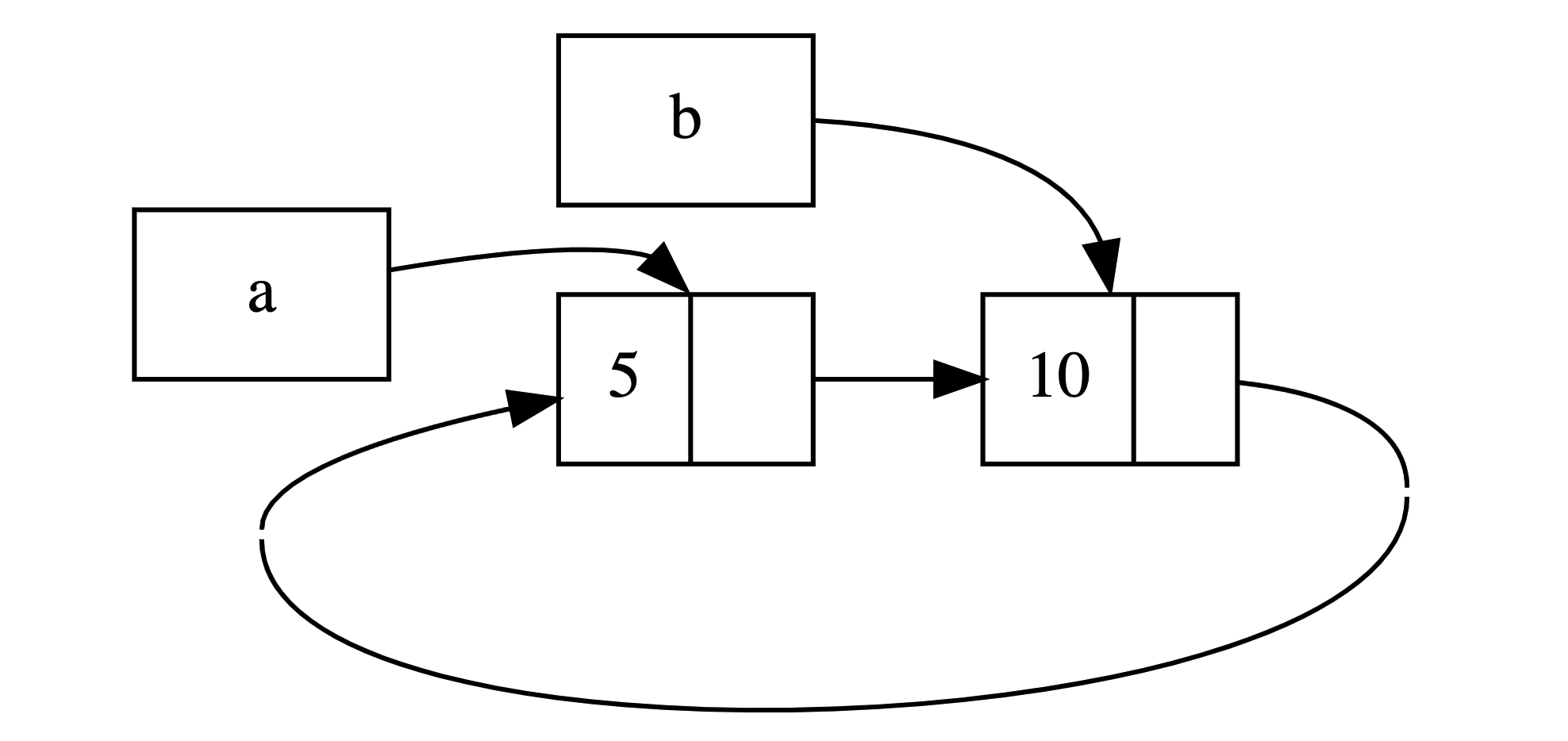
如果取消最后 println! 的注释并运行程序,Rust会尝试打印出 a 指向 b 指向 a 这样的循环直到栈溢出。
这个特定的例子中,创建了引用循环之后程序立刻就结束了。这个循环的结果并不可怕。如果在更为复杂的程序中并在循环里分配了很多内存并占有很长时间,这个程序会使用多于它所需要的内存,并有可能压垮系统并造成没有内存可供使用。
创建引用循环并不容易,但也不是不可能。如果你有包含 Rc<T> 的 RefCell<T> 值或类似的嵌套结合了内部可变性和引用计数的类型,请务必小心确保你没有形成一个引用循环;你无法指望 Rust 帮你捕获它们。创建引用循环是一个程序上的逻辑 bug,你应该使用自动化测试、 代码评审和其他软件开发最佳实践来使其最小化。
另一个解决方案是重新组织数据结构,使得一部分引用拥有所有权而另一部分没有。换句话说,循环将由一些拥有所有权的关系和一些无所有权的关系组成,只有所有权关系才能影响值是否可以被丢弃。我们总是希望 Cons 成员拥有其列表,所以重新组织数据结构是不可能的。让我们看看一个由父节点和子节点构成的图的例子,观察何时是使用无所有权的关系来避免引用循环的合适时机。
避免引用循环:将 Rc 变为 Weak
到目前为止,我们已经展示了调用 Rc::clone 会增加 Rc<T> 实例的 strong_count,和只在其 strong_count 为 0 时才会被清理的 Rc<T> 实例。你也可以通过调用 Rc::downgrade 并传递 Rc<T> 实例的引用来创建其值的 弱引用(weak reference)。调用 Rc::downgrade 时会得到 Weak<T> 类型的智能指针。不同于将 Rc<T> 实例的 strong_count 加 1,调用 Rc::downgrade 会将 weak_count 加 1。Rc<T> 类型使用 weak_count 来记录其存在多少个 Weak<T> 引用,类似于 strong_count。其区别在于 weak_count 无需计数为 0 就能使 Rc<T> 实例被清理。
强引用代表如何共享 Rc<T> 实例的所有权,但弱引用并不属于所有权关系。他们不会造成引用循环,因为任何弱引用的循环会在其相关的强引用计数为 0 时被打断。
因为 Weak<T> 引用的值可能已经被丢弃了,为了使用 Weak<T> 所指向的值,我们必须确保其值仍然有效。为此可以调用 Weak<T> 实例的 upgrade 方法,这会返回 Option<Rc<T>>。如果 Rc<T> 值还未被丢弃,则结果是 Some;如果 Rc<T> 已被丢弃,则结果是 None。因为 upgrade 返回一个 Option<Rc<T>>,Rust 会确保处理 Some 和 None 的情况,所以它不会返回非法指针。
作为一个例子,不同于使用一个某项只知道其下一项的列表,我们会创建一个某项知道其子项和父项的树形结构。
创建树形数据结构:带有子节点的 Node
让我们从一个叫做 Node 的存放拥有所有权的 i32 值和其子 Node 值引用的结构体开始:use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
我们希望能够 Node 拥有其子节点,同时也希望通过变量来共享所有权,以便可以直接访问树中的每一个 Node,为此 Vec<T> 的项的类型被定义为 Rc<Node>。我们还希望能修改其他节点的子节点,所以 children 中 Vec<Rc<Node>> 被放进了 RefCell<T>。
接下来,使用此结构体定义来创建一个叫做 leaf 的带有值 3 且没有子结点的 Node 实例,和另一个带有值 5 并以 leaf 作为子结点的实例 branchfn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}
这里克隆了 leaf 中的 Rc<Node> 并储存在了 branch 中,这意味着 leaf 中的 Node 现在有两个所有者:leaf和branch。可以通过 branch.children 从 branch 中获得 leaf,不过无法从 leaf 到 branch。leaf 没有到 branch 的引用且并不知道他们相互关联。我们希望 leaf 知道 branch 是其父节点。稍后我们会这么做。
增加从子到父的引用
为了使子节点知道其父节点,需要在 Node 结构体定义中增加一个 parent 字段。问题是 parent 的类型应该是什么。我们知道其不能包含 Rc<T>,因为这样 leaf.parent 将会指向 branch 而 branch.children 会包含 leaf 的指针,这会形成引用循环,会造成其 strong_count 永远也不会为 0。
现在换一种方式思考这个关系,父节点应该拥有其子节点:如果父节点被丢弃了,其子节点也应该被丢弃。然而子节点不应该拥有其父节点:如果丢弃子节点,其父节点应该依然存在。这正是弱引用的例子!
所以 parent 使用 Weak<T> 类型而不是 Rc<T> ,具体来说是 RefCell<Weak<Node>> 。现在 Node 结构体定义看起来像这样:use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
这样,一个节点就能够引用其父节点,但不拥有其父节点。我们更新 main 来使用新定义以便 leaf 节点可以引用其父节:fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}
创建 leaf 节点类似于之前如何创建 leaf 节点的,除了 parent 字段有所不同: leaf 开始时没有父节点,所以我们新建了一个空的 Weak 引用实例。
此时,当尝试使用 upgrade 方法获取 leaf 的父节点引用时,会得到一个 None 值。如第一个 println! 输出所示:leaf parent = None
当创建 branch 节点时,其也会新建一个 Weak 引用,因为 branch 并没有父节点。 leaf 仍然作为 branch 的一个子节点。一旦在 branch 中有了 Node 实例,就可以修改 leaf 使 其拥有指向父节点的 Weak 引用。这里使用了 leaf 中 parent 字段里的 RefCell 的borrow_mut 方法,接着使用了 Rc::downgrade 函数来从 branch 中的 Rc 值创建了一个指向 branch 的 Weak 引用。
当再次打印出 leaf 的父节点时,这一次将会得到存放了 branch 的 Some 值:现在 leaf 可以访问其父结点了! 当打印出 leaf 时,我们也避免了最终会导致栈溢出的循环: Weak 引用被打印为 (Weak) :leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
没有无限的输出表明这段代码并没有造成引用循环。这一点也可以从观察 Rc::strong_count 和 Rc::weak_count 调用的结果看出。
可视化 strong_count 和 weak_count 的改变
让我们通过创建了一个新的内部作用域并将 branch 的创建放入其中,来观察 Rc<Node> 实例的 strong_count 和 weak_count 值的变化。这会展示当 branch 创建和离开作用域被丢弃时会发生什么。fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
一旦创建了 leaf ,其 Rc 的强引用计数为 1,弱引用计数为 0。在内部作用域中创建了 branch 并与 leaf 相关联,此时 branch 中 Rc 的强引用计数为 1,弱引用计数为 1(因为 leaf.parent 通过 Weak<T> 指向 branch )。这里 leaf 的强引用计数为 2,因为现在 branch 的 branch.children 中储存了 leaf 的 Rc 的拷贝,不过弱引用计数仍然为0。
当内部作用域结束时, branch 离开作用域,其强引用计数减少为 0,所以其 Node 被丢弃。来自 leaf.parent 的弱引用计数 1 与 Node 是否被丢弃无关,所以并没有产生任何内存泄露!
如果在内部作用域结束后尝试访问 leaf 的父节点,会再次得到 None 。在程序的结尾, leaf 中 Rc 的强引用计数为 1,弱引用计数为 0,因为因为现在 leaf 又是 Rc 唯一 的引用了。
所有这些管理计数和值的逻辑都内建于 Rc 和 Weak 以及它们的 Drop trait实现中。通过在 Node 定义中指定从子结点到父结点的关系为一个 Weak<T> 引用,就能够拥有父节点和子节之间的双向引用而不会造成引用循环和内存泄露。