一、什么是所有权
Rust 的核心功能(之一)是所有权(ownership)。虽然这个功能说明起来很直观,不过它对语言的其余部分有着更深层的含义。
所有程序都必须管理其运行时使用计算机内存的方式。一些语言中使用垃圾回收在程序运行过程中来时刻寻找不再被使用的内存;在另一些语言中,程序员必须亲自分配和释放内存。
Rust 则选择了第三种方式:内存被一个所有权系统管理,它拥有一系列的规则使编译器在编译时进行检查。任何所有权系统的功能都不会导致运行时开销。
因为所有权对很多程序员来说都是一个新概念,需要一些时间来适应。好消息是随着你对 Rust 和所有权系统的规则越来越有经验,你就越能自然地编写出安全和高效的代码。持之以恒!
栈(Stack)与堆(Heap)
在很多语言中并不经常需要考虑到栈与堆。不过在像 Rust 这样的系统编程语言中,值是位于栈上还是堆上在更大程度上影响了语言的行为以及为何必须做出这样的选择。
栈和堆都是代码在运行时可供使用的内存部分,不过他们以不同的结构组成。
栈以放入值的顺序存储并以相反顺序取出值。这也被称作后进先出(last in, first out)。想象一下一叠盘子:当增加更多盘子时,把他们放在盘子堆的顶部,当需要盘子时,也从顶部拿走。不能从中间也不能从底部增加或拿走盘子!增加数据叫做进栈(pushing onto the stack),而移出数据叫做出栈(popping off the stack)。
操作栈是非常快的,因为它访问数据的方式:永远也不需要寻找一个位置放入新数据或者取出数据因为这个位置总是在栈顶。另一个使得栈快速的性质是栈中的所有数据都必须有一个已知且固定的大小。
相反对于在编译时未知大小或大小可能变化的数据,可以把他们储存在堆上。堆是缺乏组织的:当向堆放入数据时,我们请求一定大小的空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回给我们一个其位置的指针(pointer)。这个过程称作在堆上分配内存(allocating on the heap),并且有时这个过程就简称为“分配”(allocating)。向栈中放入数据并不被认为是分配。因为指针是已知的固定大小的,我们可以将指针储存在栈上,不过当需要实际数据时,必须访问指针。
想象一下去餐馆就坐吃饭。当进入时,你说明有几个人,餐馆员工会找到一个够大的空桌子并领你们过去。如果有人来迟了,他们也可以通过询问来找到你们坐在哪。
访问堆上的数据要比访问栈上的数据要慢因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。继续类比,假设有一个服务员在餐厅里处理多个桌子的点菜。在一个桌子报完所有菜后再移动到下一个桌子是最有效率的。从桌子 A 听一个菜,接着桌子 B 听一个菜,然后再桌子 A,然后再桌子 B 这样的流程会更加缓慢。出于同样原因,处理器在处理的数据之间彼此较近的时候(比如在栈上)比较远的时候(比如可能在堆上)能更好的工作。在堆上分配大量的空间也可能消耗时间。
当调用一个函数,传递给函数的值(包括可能指向堆上数据的指针)和函数的局部变量被压入栈中。当函数结束时,这些值被移出栈。
记录何处的代码在使用堆上的什么数据,最小化堆上的冗余数据的数量以及清理堆上不再使用的数据以致不至于耗尽空间,这些所有的问题正是所有权系统要处理的。一旦理解了所有权,就不需要经常考虑栈和堆了,不过理解如何管理堆内存可以帮助我们理解所有权为何存在以及为什么要以这种方式工作。
所有权规则
首先,让我们来看看所有权规则。在我们处理说明它们的示例时,请记住这些规则:
- Rust中每一个值都有一个称之为其所有者(owner)的变量。
- 值有且只能有一个所有者。
- 当所有者(变量)离开作用域,这个值将被丢弃。
变量范围
现在我们已经掌握了基本语法,所以不会在之后的例子中包含 fn main() { 代码了,必须手动将之后例子的代码放入一个 main 函数中。为此,例子将显得更加简明,使我们可以关注具体细节而不是样板代码。
作为所有权的第一个例子,我们看看一些变量的作用域(scope)。作用域是一个项(原文: item)在程序中有效的范围。假设有这样一个变量:let s = "hello";
变量 s 绑定到了一个字符串字面值,这个字符串值是硬编码进程序代码中的。这个变量从声明的点开始直到当前作用域结束时都是有效的。{
let s = "hello";
}
这里有两个重要的点:
- 当 s 进入作用域时,它就是有效的。
- 这一直持续到它离开作用域为止。
变量是否有效与作用域的关系跟其他编程语言是类似的。现在我们在此基础上介绍 String 类型。
- 这一直持续到它离开作用域为止。
String 类型
前面介绍的类型都是已知大小的,可以存储在堆栈中并弹出当它们的作用域结束时离开堆栈,如果代码的另一部分需要在不同的作用域中使用相同的值,可以快速而简单地复制以创建一个新的独立实例。但是我们想查看存储在堆上的数据,并探索 Rust 如何知道何时清理这些数据。
我们将String在此处用作示例,并专注于String 与所有权相关的部分。这些方面也适用于其他复杂数据类型,无论它们是由标准库提供的还是由您创建的。
我们已经看到了字符串字面值,其中一个字符串值被硬编码到我们的程序中。字符串字面值很方便,但它们并不适合我们可能想要使用文本的所有情况。原因之一是它们是不可变的。另一个是在我们编写代码时并不是每个字符串值都可以知道:例如,如果我们想要获取用户输入并存储它怎么办?对于这些情况,Rust 有第二个字符串类型,String。这种类型管理在堆上分配的数据,因此能够存储我们在编译时未知的大量文本。您可以String使用该from函数从字符串文字创建 a ,let s = String::from("hello");
这两个冒号(::)运算符允许将特定的 from 函数置于 String 类型的命名空间(namespace)下而不需要使用类似 string_from 这样的名字。
这类字符串可以被修改:let mut s = String::from("hello");
s.push_str(", world!"); // push_str() appends a literal to a String
println!("{}", s); // This will print `hello, world!`
为什么 String 可变而字面值却不行呢?区别在于两个类型对内存的处理上。
内存和分配
对于字符串文字,我们在编译时就知道内容,因此文本被直接硬编码到最终的可执行文件中。这就是字符串文字快速高效的原因。但是这些属性仅来自字符串文字的不变性。不幸的是,对于在编译时大小未知且在运行程序时其大小可能会发生变化的每段文本,我们无法将大量内存放入二进制文件中。
对于String类型,为了支持可变的、可增长的文本片段,我们需要在编译时未知的堆上分配大量内存来保存内容。这意味着:
- 内存必须在运行时向操作系统请求。
- 需要一个当我们处理完 String 时将内存返回给操作系统的方法。
第一部分由我们完成:当调用 String::from 时,它的实现 (implementation) 请求其所需的内存。这在编程语言中是非常通用的。
但是,第二部分不同。在带有垃圾收集器 (GC) 的语言中,GC 会跟踪并清理不再使用的内存,我们不需要考虑它。如果没有 GC,我们有责任确定何时不再使用内存并调用代码显式返回它,就像我们请求它一样。正确地做到这一点在历史上一直是一个困难的编程问题。如果我们忘记了,我们就会浪费记忆。如果我们做得太早,我们将有一个无效的变量。如果我们做两次,那也是一个错误。我们需要将恰好一allocate与恰好一配对free。
Rust 采取了不同的路径:一旦拥有它的变量超出范围,内存就会自动返回。{
let s = String::from("hello"); // 从这一点开始s是有效的
// 用s做事
} // 这个范围现在已经结束了,s不存在
// 不再有效
一个将 String 需要的内存返回给操作系统的很自然的位置:当 s 离开作用域的时候。当变量离开作用域,Rust 为其调用一个特殊的函数。这个函数叫做 drop ,在这里String 的作者可以放置释放内存的代码。Rust 在结尾的 } 处自动调用 drop 。
注意:在 C++ 中,这种 item 在生命周期结束时释放资源的方法有时被称作资源获取即初始化(Resource Acquisition Is Initialization (RAII))。如果你使用过 RAII 模式的话应该对 Rust 的 drop 函数并不陌生。
这个模式对编写 Rust 代码的方式有着深远的影响。现在它看起来很简单,不过在更复杂的场景下代码的行为可能是不可预测的,比如当有多个变量使用在堆上分配的内存时。现在让我们探索一些这样的场景。
变量和数据交互的方式:移动
在 Rust 中,多个变量可以以不同的方式与相同的数据交互。let x = 5;
let y = x;
我们大致可以猜到这在干什么:“将 5 绑定到 x;接着生成一个值 x 的拷贝并绑定到 y”。现在有了两个变量,x 和 y,都等于 5。这也正是事实上发生了的,因为整数是有已知固定大小的简单值,所以这两个 5 被放入了栈中。
现在让我们看看String版本:let s1 = String::from("hello");
let s2 = s1;
这看起来与前面的代码非常相似,所以我们可能假设它的工作方式是相同的:也就是说,第二行将复制值s1并将其绑定到s2。但这并不完全是发生的事情。
为了更全面的解释这个问题,让我们看看下图中 String 真正是什么样的。 String 由三部分组成,如图左侧所示:一个指向存放字符串内容内存的指针,一个长度,和一个容量。 这一组数据储存在栈上。右侧则是堆上存放内容的内存部分。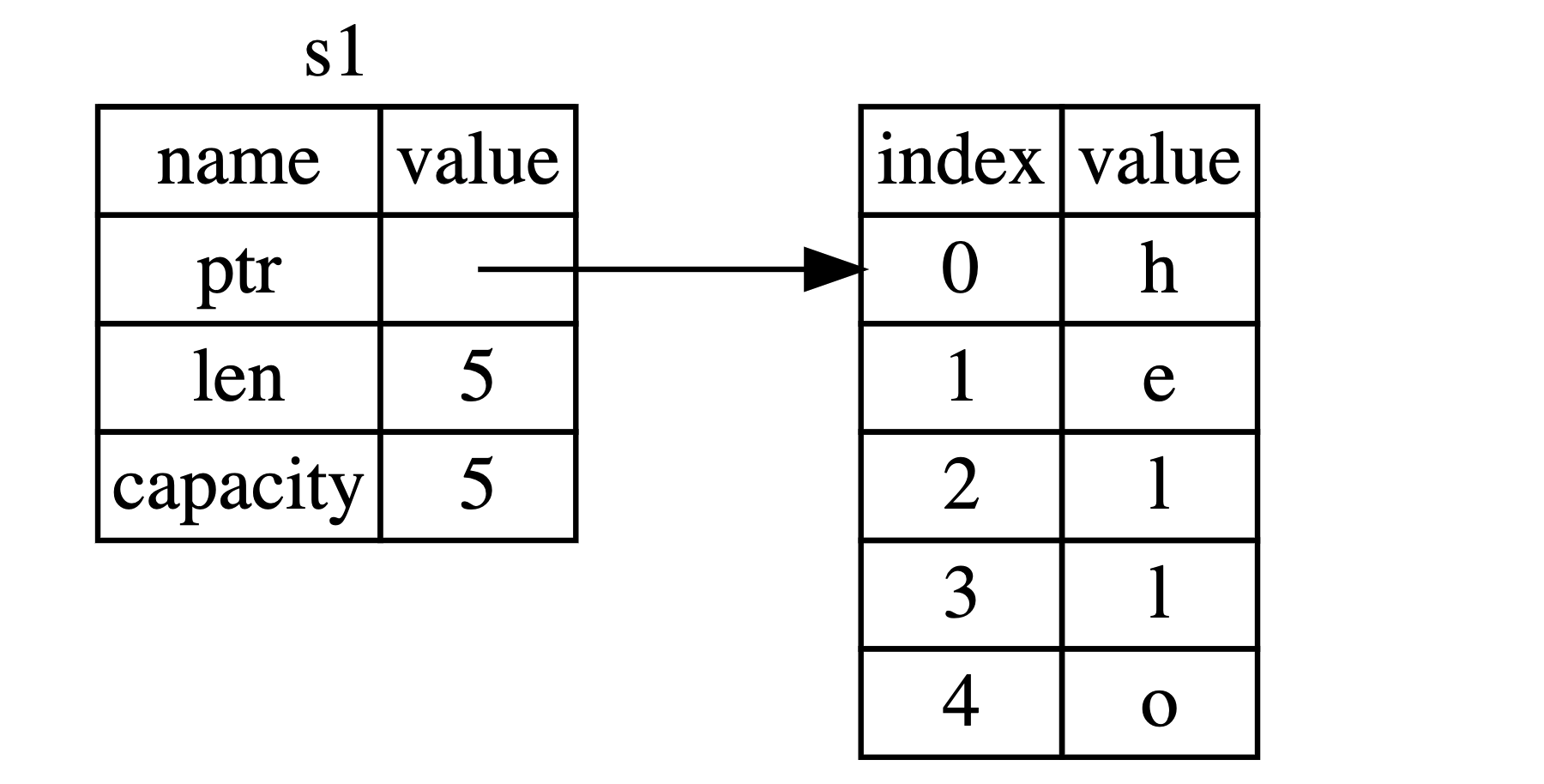
长度代表当前 String 的内容使用了多少字节的内存。容量是 String 从操作系统总共获取了多少字节的内存。
当我们把 s1 赋值给 s2 , String 的数据被复制了,这意味着我们从栈上拷贝了它的指针、长度和容量。我们并没有复制堆上指针所指向的数据。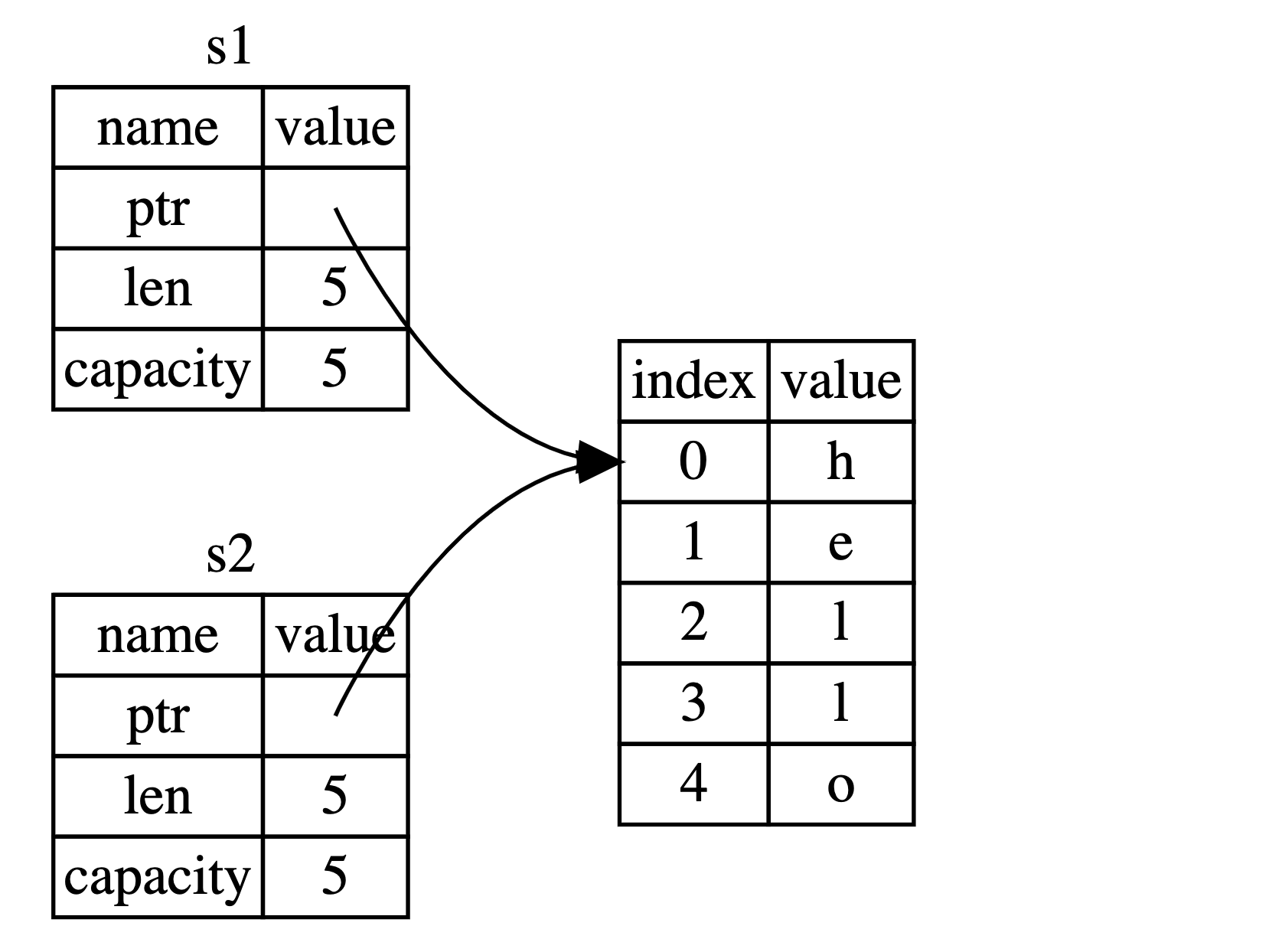
这个表现形式看起来并不像下图的那样,如果 Rust 也拷贝了堆上的数据后内存看起来会是如何呢。如果 Rust 这么做了,那么操作 s2 = s1 在堆上数据比较大的时候可能会对运行时性能造成非常大的影响。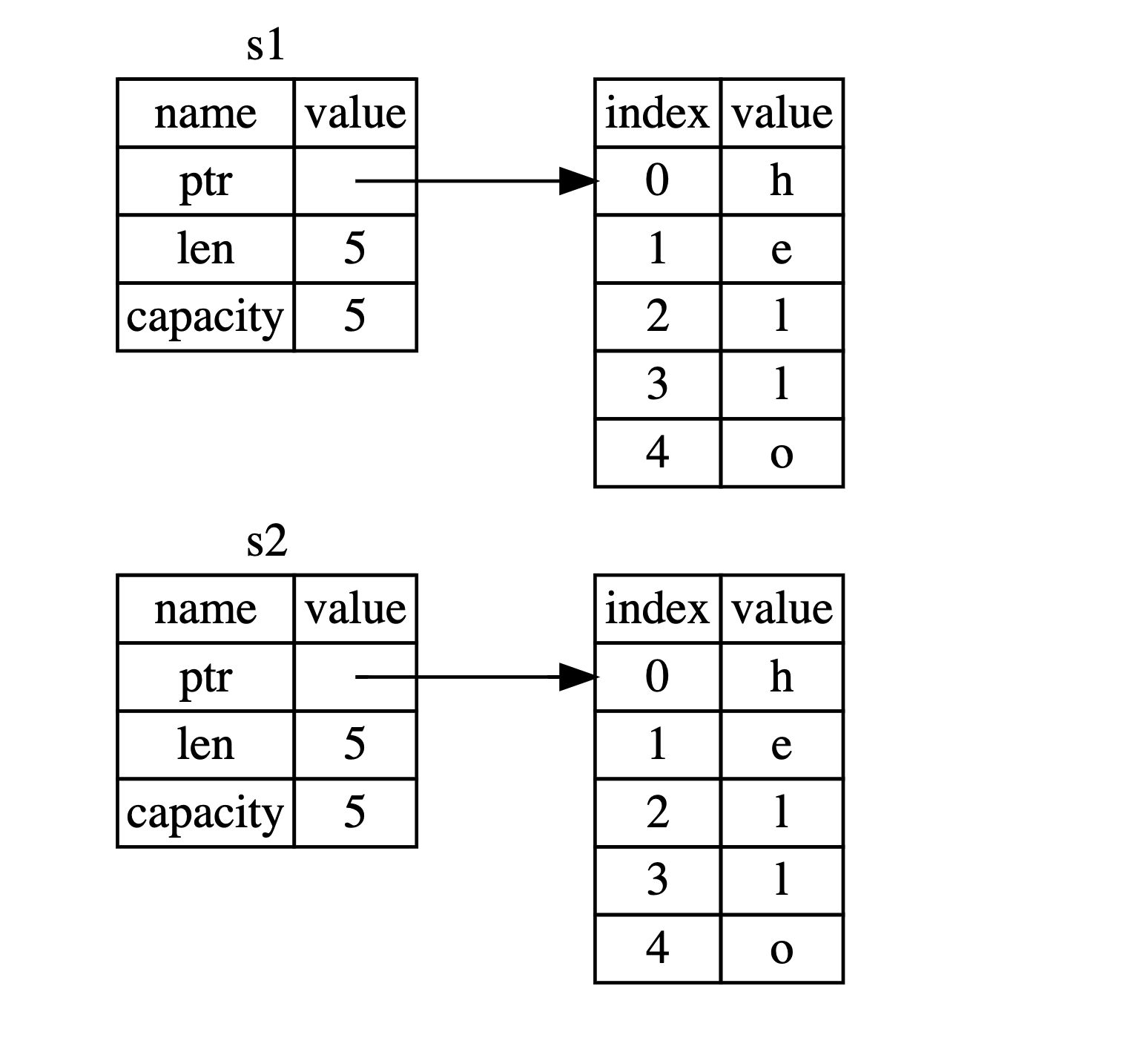
早些时候,我们说过当变量超出作用域时,Rust 会自动调用该drop函数并清理该变量的堆内存。但是第二张图显示了两个数据指针指向同一位置。这是一个问题:当s2和s1超出范围时,它们都会尝试释放相同的内存。这被称为二重释放,是我们之前提到的内存安全错误之一。两次释放内存会导致内存损坏,这可能会导致安全漏洞。
为了确保内存安全,在 Rust 中,在这种情况下会发生什么,还有一个细节。之后let s2 = s1,Rust 认为s1不再有效。因此,Rust 在s1超出范围时不需要释放任何东西。查看s1在s2创建后尝试使用时会发生什么;它不会工作:let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
你会得到这样的错误,因为 Rust 阻止你使用无效的引用:cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` due to previous error
如果你在其他语言中听说过术语“浅拷贝”(“shallow copy”)和“深拷贝”(“deep copy”),那么拷贝指针、长度和容量而不拷贝数据可能听起来像浅拷贝。不过因为 Rust 同时使第一个变量无效化了,这个操作被称为移动(move),而不是浅拷贝。上面的例子可以解读为 s1 被移动到了 s2 中。看看下图: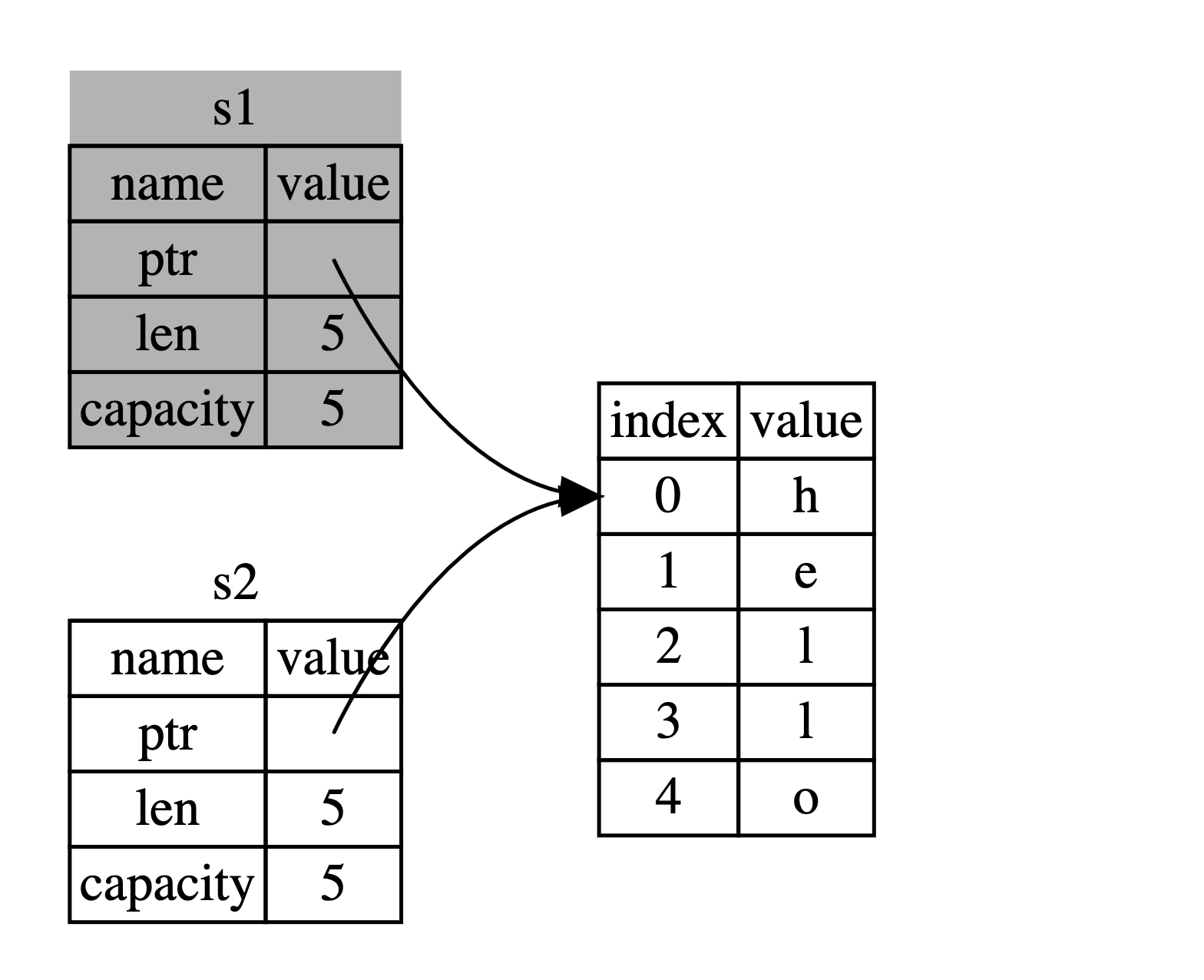
s1失效后内存中的表示,这解决了我们的问题!只有s2有效,当它超出范围时,它才会释放内存,我们就完成了。
另外,这里还隐含了一个设计选择:Rust 永远也不会自动创建数据的“深拷贝”。因此,任何自动的复制可以被认为对运行时性能影响较小。
变量和数据交互的方式:克隆
如果我们确实需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的通用函数。
这是一个实际使用 clone 方法的例子:let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
当出现 clone 调用时,你知道一些特定的代码被执行而且这些代码可能相当消耗资源。你很容易察觉到一些不寻常的事情正在发生。
仅栈数据:复制
这里还有一个没有提到的小窍门。let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
他们似乎与我们刚刚学到的内容相抵触:没有调用 clone ,不过 x 依然有效且没有被移动到 y 中。原因是诸如在编译时已知大小的整数之类的类型完全存储在堆栈中,因此可以快速制作实际值的副本。这意味着我们没有理由希望x在创建变量后阻止其有效y。换句话说,这里的深拷贝和浅拷贝没有区别,所以调用clone与通常的浅拷贝没有什么不同,我们可以省略它。
Rust 有一个叫做 Copy trait 的特殊注解,可以用在类似整型这样的储存在栈上的类型。如果一个类型拥有 Copy trait,一个旧的变量在将其赋值给其他变量后仍然可用。Rust 不允许自身或其任何部分实现了 Drop trait 的类型使用 Copy trait。如果我们对其值离开作用域时需要特殊处理的类型使用 Copy 注解,将会出现一个编译时错误。
那么什么类型是 Copy 的呢?可以查看给定类型的文档来确认,不过作为一个通用的规则,任何简单标量值的组合可以是 Copy 的,任何需要分配内存,或者本身就是某种形式资源的类型不会是 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如 u32 。
- 布尔类型, bool ,它的值是 true 和 false 。
- 所有浮点数类型,比如 f64 。
- 字符类型,char。
- 元组,当且仅当其包含的类型也都是 Copy 的时候。 (i32, i32) 是 Copy 的,不过(i32, String)就不是。
所有权与函数
将值传递给函数在语义上与给变量赋值相似。向函数传递值可能会移动或者复制,就像赋值语句一样。fn main() {
let s = String::from("hello"); // s进入范围
takes_ownership(s); // s的值移动到函数中。。。
// ... 因此在这里不再有效
let x = 5; // x进入范围
makes_copy(x); // x将进入函数,
// 但i32是复制的,所以可以继续
// 之后使用x
} // 这里,x超出范围,然后是s。但是因为s的值被移动了,所以什么都没有特殊情况会发生。
fn takes_ownership(some_string: String) { // some_string 字符串进入范围
println!("{}", some_string);
} // 这里,some_string字符串超出了范围,调用了'drop'。支持内存被释放。
fn makes_copy(some_integer: i32) { // some_integer 进入范围
println!("{}", some_integer);
} // 在这里,some_integer整数超出了范围。没有什么特别的事情发生。
当尝试在调用 takes_ownership 后使用 s 时,Rust 会抛出一个编译时错误。这些静态检查使我们免于犯错。试试在 main 函数中添加使用 s 和 x 的代码来看看哪里能使用他们, 以及所有权规则会在哪里阻止我们这么做。
返回值与作用域
返回值也可以转移作用域。fn main() {
let s1 = gives_ownership(); // 将其返回值移动到s1中
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2被移到takes_and_gives_back中,这也将其返回值移到s3中
} // 在这里,s3超出了范围并被删除。s2被移动了,所以什么也没发生。s1超出范围并被删除。
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string 字符串进入范围
some_string // some_string 返回并移到调用函数
}
// This function takes a String and returns one
fn takes_and_gives_back(a_string: String) -> String { // a_string comes into
// scope
a_string // a_string 返回并移到调用函数
}
变量的所有权总是遵循相同的模式:将值赋值给另一个变量时移动它。当持有堆中数据值的变量离开作用域时,其值将通过 drop 被清理掉,除非数据被移动为另一个变量所有。
在每一个函数中都获取并接着返回所有权可能有些冗余。如果我们想要函数使用一个值但不获取所有权该怎么办呢?如果我们还要接着使用它的话,每次都传递出去再传回来就有点烦人了,另外我们也可能想要返回函数体产生的任何(不止一个)数据。
可以使用元组来返回多个值,像这样:fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() returns the length of a String
(s, length)
}
但是这未免有些形式主义,而且这种场景应该很常见。幸运的是,Rust 对此提供了一个功能,叫做引用(references)。
二、引用与借用
上一部分结尾的元组代码有这样一个问题:我们不得不将 String 返回给调用函数,以便仍能在调用 calculate_length 后使用 String ,因为 String 被移动到了 calculate_length 内。
引用(reference)像一个指针,因为它是一个地址,我们可以由此访问储存于该地址的属于其他变量的数据。与指针不同,引用确保指向某个特定类型的有效值。
以下是如何定义和使用calculate_length将对象引用作为参数而不是获取值的所有权的函数:fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
首先,注意变量声明和函数返回值中的所有元组代码都消失了。其次,注意我们传递 &s1 给 calculate_length ,同时在函数定义中,我们获取 &String 而不是 String 。
这些 & 符号就是引用,他们允许你使用值但不获取其所有权。如下图: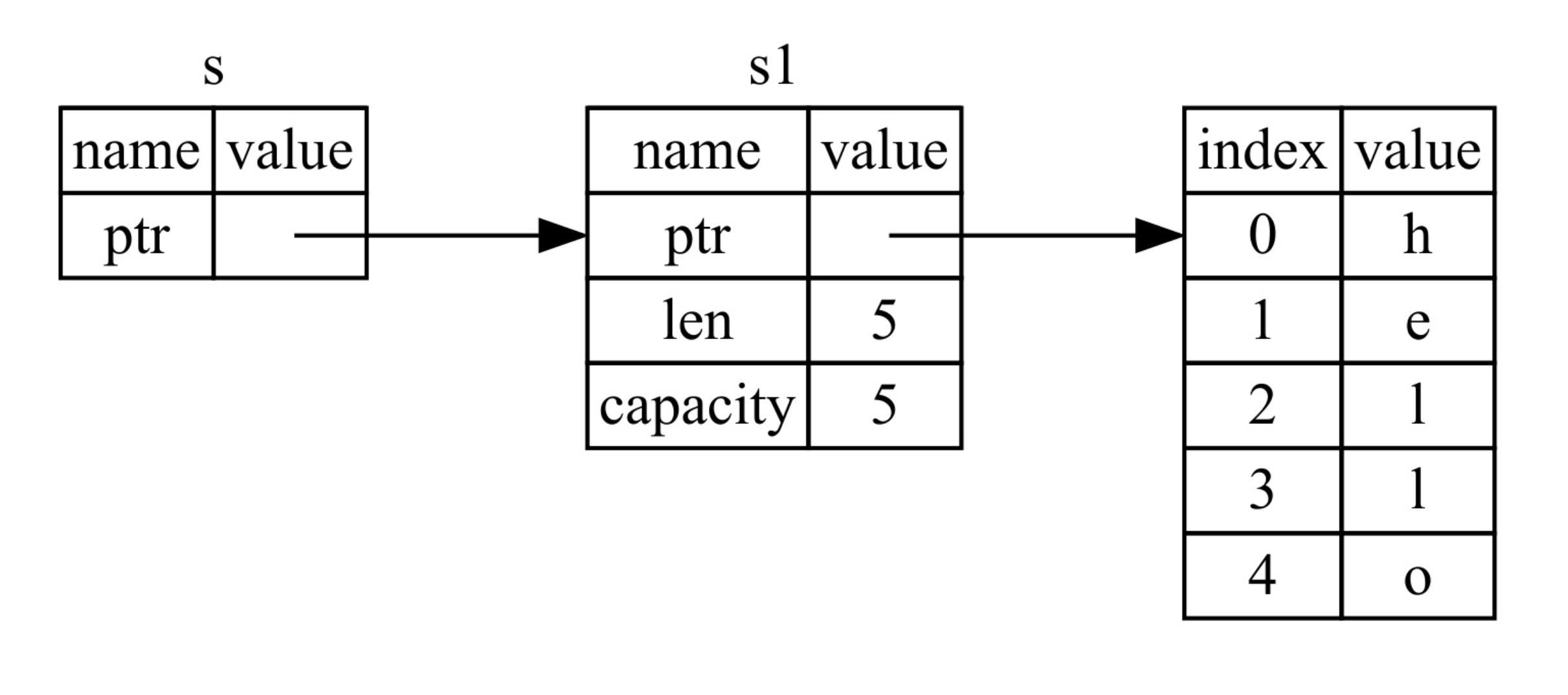
&String s 指向 String s1。
注意:与使用 & 引用相对的操作是 解引用(dereferencing),它使用解引用运算符, * 。。
仔细看看这个函数调用:let s1 = String::from("hello");
let len = calculate_length(&s1);
&s1 语法允许我们创建一个指向值 s1 的引用,但是并不拥有它。因为并不拥有这个值,当引用离开作用域时其指向的值也不会被丢弃。同理,函数签名使用了 & 来表明参数 s 的类型是一个引用。让我们增加一些解释性的注解:fn calculate_length(s: &String) -> usize { // s is a reference to a String
s.len()
} // 这里,s超出了范围。但因为它没有什么所有权它指的是什么都没有发生。
变量 s 有效的作用域与函数参数的作用域一样,不过当引用离开作用域后并不丢弃它指向的数据,因为我们没有所有权。函数使用引用而不是实际值作为参数意味着无需返回值来交还所有权,因为就不曾拥有所有权。
我们将获取引用作为函数参数称为借用(borrowing)。正如现实生活中,如果一个人拥有某样东西,你可以从他那里借来。当你使用完毕,必须还回去。
如果我们尝试修改借用的变量呢?fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}
这里是错误:error[E0596]: cannot borrow immutable borrowed content `*some_string` as mutable --> error.rs:8:5
|
7 | |
8 | |
fn change(some_string: &String) {
------- use `&mut String` here to make mutable
some_string.push_str(", world"); ^^^^^^^^^^^ cannot borrow as mutable
正如变量默认是不可变的,引用也一样。(默认)不允许修改引用的值。
可变引用
我们可以通过一些小的调整来修复上述代码的错误:fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
首先,我们必须更改s为mut。然后我们必须&mut s在调用change函数的地方创建一个可变引用,并更新函数签名以接受一个带有的可变引用some_string: &mut String。这清楚地表明该change函数将改变它借用的值。
但是可变引用有一个很大的限制:一次只能有一个对特定数据的可变引用。此代码将报错:let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
这里报错:cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` due to previous error
此错误表示此代码无效,因为我们不能一次多次借用可变变量。
防止同时对同一数据进行多个可变引用的限制允许以非常受控的方式进行突变。
数据竞争(data race)是一种特定类型的竞争状态,它可由这三个行为造成:
- 两个或更多指针同时访问同一数据。
- 至少有一个这样的指针被用来写入数据。
- 不存在同步数据访问的机制。
数据竞争会导致未定义行为,难以在运行时追踪,并且难以诊断和修复;Rust 避免了这种情况的发生,因为它甚至不会编译存在数据竞争的代码!
一如既往,可以使用大括号来创建一个新的作用域来允许拥有多个可变引用,只是不能同时拥有:当结合可变和不可变引用时有一个类似的规则存在。这些代码会导致一个错误:let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1超出了这里的范围,所以我们可以毫无问题地创建一个新的引用。
let r2 = &mut s;这是错误:let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{}, {}, and {}", r1, r2, r3);我们也不能在拥有不可变引用的同时拥有可变引用。不可变引用的用户可不希望在它的眼皮底下值突然就被改变了!然而,多个不可变引用是没有问题的因为没有哪个只能读取数据的人有能力影响其他人读取到的数据。cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
- 不存在同步数据访问的机制。
请注意,引用的范围从它被引入的地方开始,一直持续到最后一次使用该引用。例如,此代码将编译,因为最后一次使用不可变引用println!, 发生在引入可变引用之前:let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
println!("{} and {}", r1, r2);
// variables r1 and r2 will not be used after this point
let r3 = &mut s; // no problem
println!("{}", r3);
不可改变的引用的范围r1和r2结束后println!,他们最后被使用,这是可变的引用之前r3被创建。这些范围不重叠,因此允许使用此代码。编译器在作用域结束之前判断不再使用引用的能力称为非词法生命周期(简称 NLL)。
悬垂引用(Dangling References)
在存在指针的语言中,容易通过释放内存时保留指向它的指针而错误地生成一个悬垂指针(dangling pointer),所谓悬垂指针是其指向的内存可能已经被分配给其它持有者。相比之下,在 Rust 中编译器确保引用永远也不会变成悬垂状态:当我们拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域。
让我们尝试创建一个悬垂引用,Rust 会通过一个编译时错误来避免:fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
这是错误:cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| ^^^^^^^^
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` due to previous error
错误信息引用了一个我们还未涉及到的功能:生命周期(lifetimes)。
仔细看看我们的 dangle 代码的每一步到底发生了什么:fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // 我们返回对字符串s的引用
} // 在这里,s超出范围,被删除。它的记忆消失了。
// 危险!
因为 s 是在 dangle 函数内创建的,当 dangle 的代码执行完毕后, s 将被释放。不过我们尝试返回一个它的引用。这意味着这个引用会指向一个无效的 String !
这里的解决方法是直接返回 String :fn no_dangle() -> String {
let s = String::from("hello");
s
}
这没有任何问题。所有权被移出,没有任何东西被释放。
引用的规则总结
让我们简要的概括一下之前对引用的讨论:
- 在任意给定时间,只能拥有如下中的一个:
- 一个可变引用。
- 任意数量的不可变引用。
- 在任意给定时间,只能拥有如下中的一个:
- 引用必须总是有效的。
三、切片类型(slice)
另一种没有所有权的数据类型是切片(slice)。slice 可以引用集合中连续的元素序列,而不是整个集合。slice 是一类引用,所以它没有所有权。
这是一个小编程问题:编写一个函数,它接受一个字符串并返回它在该字符串中找到的第一个单词。如果函数在字符串中没有找到空格,则整个字符串必须是一个单词,因此应返回整个字符串。
让我们想想这个函数的签名:fn first_word(s: &String) -> ?
这个函数,first_word,有一个&String作为参数。我们不想要所有权,所以这很好。但是我们应该返回什么?我们并没有一个真正获取部分字符串的办法。不过,我们可以返回单词结尾的索引。fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
因为我们需要String逐个元素遍历并检查值是否为空格,所以我们将String使用以下as_bytes方法将其转换为字节数组:let bytes = s.as_bytes();
接下来,我们使用以下iter方法在字节数组上创建一个迭代器:for (i, &item) in bytes.iter().enumerate() {
现在,只需知道 iter 方法返回集合中的每一个元素,而 enumerate 包装 iter 的结果并返回一个元组,其中每一个元素是元组的一部分。返回元组的第一个元素是索引,第二个元素是集合中元素的引用。这比我们自己计算索引要方便一些。
因为 enumerate 方法返回一个元组,我们可以使用模式来解构。所以在 for 循环中,我们指定了一个模式,其中 i 是元组中的索引而&item 则是单个字节。因为我们从.iter().enumerate()中获取了集合元素的引用,所以模式中使用了 & 。
在for循环内部,我们使用字节文字语法搜索表示空间的字节。如果我们找到一个空格,我们就返回位置。否则,我们通过使用返回字符串的长度s.len(): if item == b' ' {
return i;
}
}
s.len()
现在有了一个找到字符串中第一个单词结尾索引的方法了,不过这有一个问题。我们返回了单独一个 usize ,不过它只在 &String 的上下文中才是一个有意义的数字。换句话说,因为它是一个与 String 相分离的值,无法保证将来它仍然有效。fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word将获得值5
s.clear(); // 这将清空字符串,使其等于“”
// word在这里仍然有值5,但是没有更多的字符串可以有意义地使用值5。这个词现在完全无效了!
}
这个程序编译时没有任何错误,而且在调用 s.clear() 之后使用 word 也不会出错。这时 word 与 s 状态就完全没有联系了,所以 word 仍然包含值 5 。可以尝试用值 5 来提取变量 s 的第一个单词,不过这是有 bug 的,因为在我们将 5 保存到 word 之后 s 的容已经改变。
我们不得不时刻担心 word 的索引与 s 中的数据不再同步,这是冗余且容易出错的!如果编写这么一个 second_word 函数的话,管理索引这件事将更加容易出问题。它的签名看起来像这样:fn second_word(s: &String) -> (usize, usize) {
现在我们跟踪了一个开始索引和一个结尾索引,同时有了更多从数据的某个特定状态计算而来的值,他们也完全没有与这个状态相关联。现在有了三个飘忽不定的不相关变量都需要被同步。
Rust 有一个解决这个问题的方法:字符串切片。
字符串切片
字符串切片是字符串中一部分值的引用,它看起来像这样:let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
这类似于获取整个 String 的引用不过带有额外的 [0..5] 部分。不同于整个 String 的引用,这是一个包含 String 内部的一个位置和所需元素数量的引用。 start..end 语法代表一个以 start 开头并一直持续到但不包含 end 的 range。
使用一个由中括号中的 [starting_index..ending_index] 指定的 range 创建一个切片,其中 starting_index 是包含在切片的第一个位置, ending_index 则是切片最后一个位置的后一个值。在其内部,切片的数据结构储存了开始位置和切片的长度,长度对应 ending_index 减去 starting_index 的值。所以对于 let world = &s[6..11]; 的情况, world 将是一个包含指向 s 第 6 个字节的指针和长度值 5 的切片。
下图说明这一点: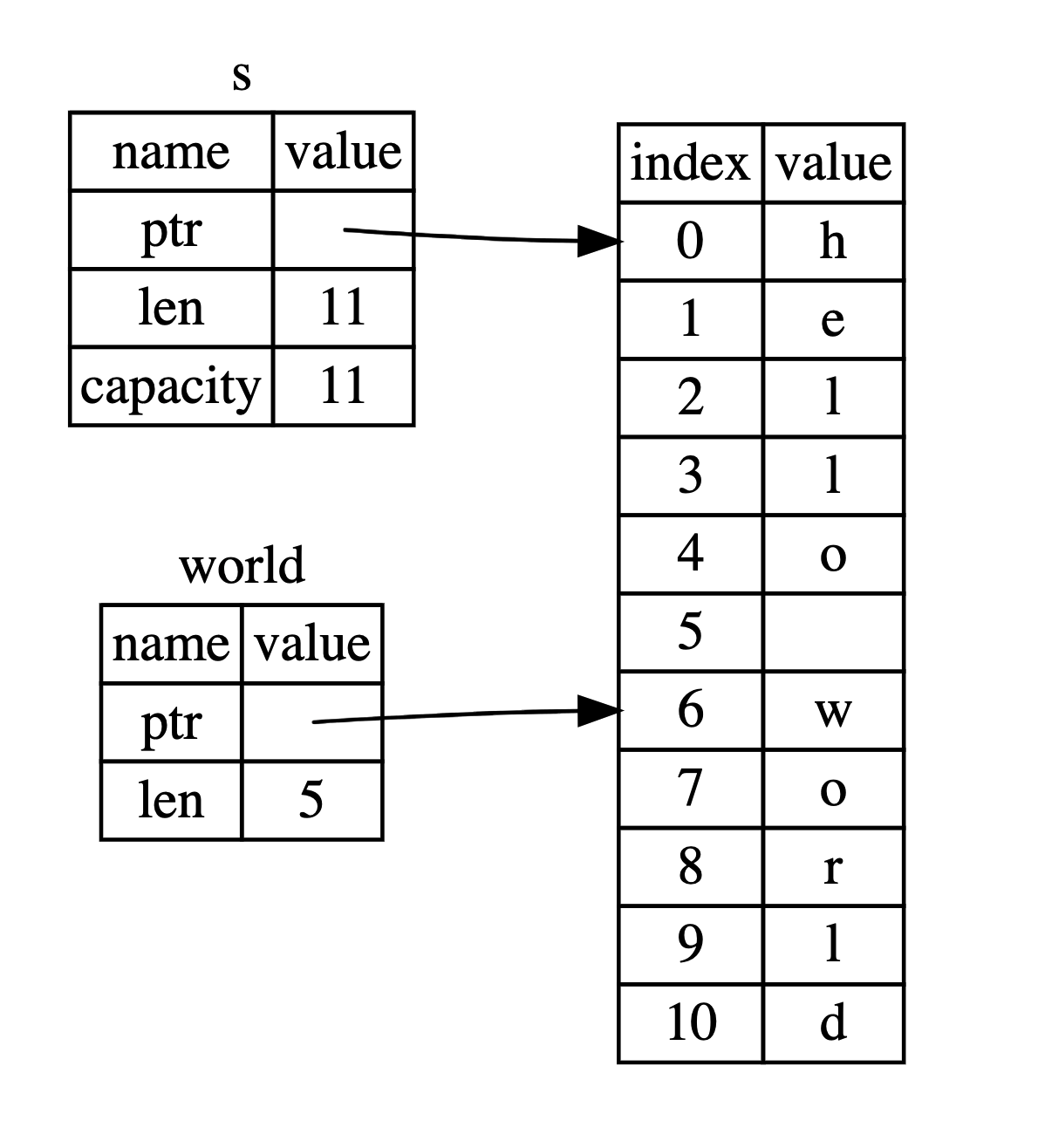
对于 Rust 的 ..range 语法,如果想要从第一个索引(0)开始,可以不写两个点号之前的值。换句话说,如下两个语句是相同的:let s = String::from("hello");
let slice = &s[0..2]; let slice = &s[..2];
由此类推,如果 slice 包含 String 的最后一个字节,也可以舍弃尾部的数字。这意味着如下也是相同的:let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
也可以同时舍弃这两个值来获取一个整个字符串的 slice。所以如下亦是相同的:let s = String::from("hello"); let len = s.len();
let slice = &s[0..len]; let slice = &s[..];
注意:字符串 slice range 的索引必须位于有效的 UTF-8 字符边界内,如果尝试从一个多字节字符的中间位置创建字符串 slice,则程序将会因错误而退出。
考虑到所有这些信息,让我们重写first_word以返回一个切片。表示“字符串切片”的类型写为&str:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
通过寻找第一个出现的空格。当找到一个空格,我们返回一个索引,它使用字符串的开始和空格的索引来作为开始和结束的索引。
现在,当我们调用时first_word,我们会返回一个与基础数据相关联的值。该值由对切片起点的引用和切片中的元素数量组成。
返回切片也适用于second_word函数:
fn second_word(s: &String) -> &str {
现在我们有了一个不易混淆且直观的 API 了,因为编译器会确保指向 String 的引用持续有效。
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
这是编译器错误:
cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
当拥有某值的不可变引用时,就不能再获取一个可变引用。因为 clear 需要清空 String ,它尝试获取一个可变引用,它失败了。Rust 不仅使得我们的 API 简单易用,也在编译时就消除了一整类的错误!
字符串文字是切片
现在我们了解了切片,我们可以正确理解字符串文字:let s = "Hello, world!";
s这里的类型是&str:它是一个指向二进制特定点的切片。这也是字符串文字不可变的原因;&str是一个不可变的引用。
字符串切片作为参数
知道您可以对文字和String值进行切片,这使我们对 进行了另一项改进first_word,这就是它的签名:fn first_word(s: &String) -> &str {
更有经验的 Rustacean 会编写下面的签名,因为它允许我们对&String值和&str值使用相同的函数。fn first_word(s: &str) -> &str {
如果我们有一个字符串切片,我们可以直接传递它。如果我们有String,我们可以传递的切片String或对的引用String。这种灵活性利用了deref强制转换。
其他切片
正如您想象的那样,字符串切片是特定于字符串的。但也有更通用的切片类型。考虑这个数组:let a = [1, 2, 3, 4, 5];
正如我们可能想要引用字符串的一部分一样,我们可能想要引用数组的一部分。我们会这样做:let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
该切片的类型为&[i32]。它的工作方式与字符串切片相同,通过存储对第一个元素的引用和长度。将把这种切片用于各种其他集合。